
Lecture 16.~18. Scheduling
목적
추상적으로는 아래의 두 가지를 결정하기 위함입니다.
- 하나의 프로세스가 얼마나 많은 시간 수행될 것인가?
- 어떤 프로세스가 수행될 것인가?
CPU 스케줄러는 ready queue에서 기다리고 있는 하나를 골라서 CPU에서 돌아가게 합니다. 앞으로의 설명은 모든 프로세스가 메모리 안에 있고, 하나의 프로세스만 CPU에서 실행된다고 가정하겠습니다. 스케줄링은 CPU 효용을 극대화하기 위해서 결정적인 부분입니다.
구체적으로는 아래와 같은 목표를 가지고 있습니다.
User-oriendted scheduling policy goals
- Minimize average-response-time : 요청을 받았을 때부터 실제로 해당 프로세스가 시작될 때까지의 시간
- Minimizs turnaround time : 해당 프로세스가 시작한 순간부터 끝날 때까지의 시간
- Minimizs variance of average response time : 프로세스의 수행 시간을 예측하는 것은 중요한 문제입니다. 평균 응답시간의 분산이 작아야 매번 비슷한 시간 내에 수행됨을 보장할 수 있습니다.
- Maximizing number of interactive users : 적절한 응답을 받는 유저의 수를 최대화
System-oriendted scheduling policy goals
- Maximize throughput : 단위 시간 동안처리되는 프로세스의 수
- Maximize processor utilization : CPU가 업무를 수행하고 있는 시간의 비율
Other Goals
- Fairness : 유저나 OS의 간섭이 없을 때 모든 프로세스는 동일하게 대응 되어야하며 starvation을 겪게 해서는 안됩니다.
- Balance resources : 모든 자원(CPU, Memory, Disk, I/O etc.)등을 모두 골고루 바쁘게할 수록 좋습니다.
Preemptive ? Non-Preemptive ?
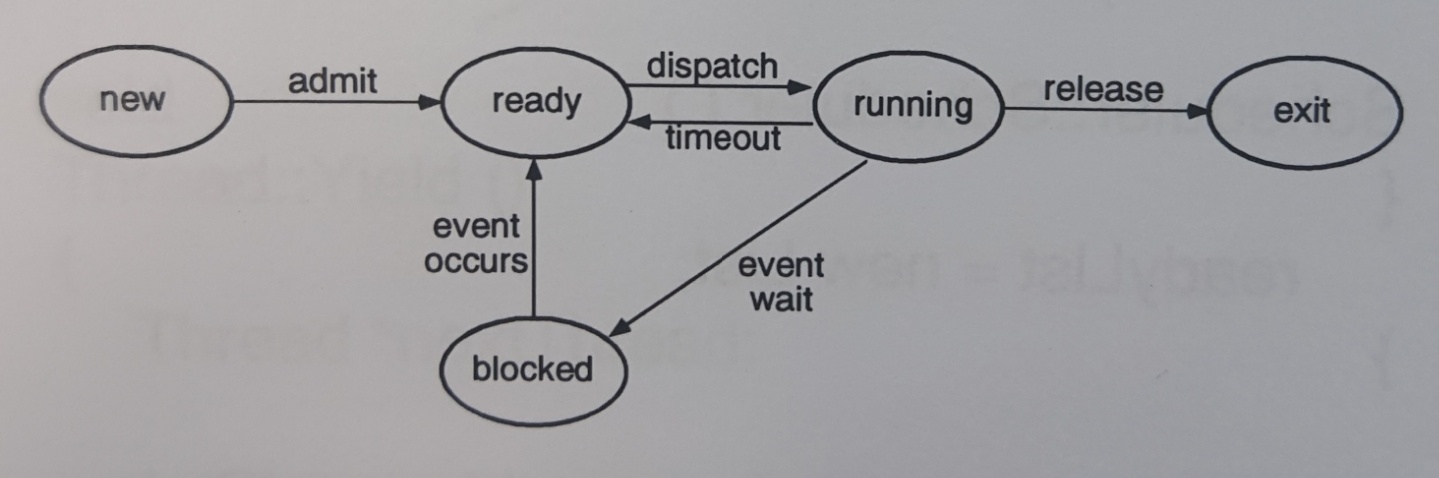
- Read -> Running : dispatch
- Blocked(Wait) -> Ready : wake-up(Event occurs)
- Running -> Ready : timeout
- Running -> Exit : Release
- Running -> Blocked(Wait) : interrupt(Event wait)
Preemptive Scheduling
스케줄러가 1.~5.의 모든 스케줄링을 직접 수행합니다. 어떤 프로세스가 실행되다가 time-slice를 모두 사용해서 time-our되거나 I/O가 발생하거나 Event를 기다려야 하는 상황이라면 다른 프로세스에게 CPU 사용을 양보합니다. 즉, CPU를 사용중인 프로세스를 중단 시키고 다른 프로세스가 CPU를 사용하도록 할 수 있습니다. 이 때 어떤 프로세스가 CPU를 사용할 것이지 결정하는 방법이 우선순위입니다.
스케줄링 오버헤드가 높지만 하나의 프로세스가 CPU를 독점하는 것을 막을 수 있습니다.
OS Kernel이 파일을 읽는 것과 같은 시스템 콜을 수행하는 동안에는 preempt 시키면 안됩니다.
Non-Preemptive Scheduling
스케줄러가 4.와 5.의 스케줄링만 직접 수행합니다. 어떤 프로세스가 CPU를 할당받으면 terminate 되거나 I/O Job을 하면서 자발적으로 Block될 때까지 수행합니다. 이 두 가지 경우에만 다름 프로세서가 수행됩니다. 멀티 프로세싱 환경에서는 특정 작업이 끝날 때까지 계속 수행 되기 때문에 멀티 프로세서의 동작을 보장할 수 없습니다.
Process Execution Behavior
가정
- 한 유저 당 하나의 프로세스
- 한 프로세스 당 하나의 쓰레드
- 프로세스들은 독립적이고 resource(CPU)를 위해서 경쟁한다.
CPU burst 또는 I/O burst에 있는 프로세스
- 잠시 동안 실행된다.
- I/O를 진행한다.
- 1.과 2.를 반복한다.
- CPU-bound : mostly computation, very little I/O
- I/O-bound : mostly I/O, very little computation
FCFS or FIFO or Run-Until-Done
레드 큐에 있는 프로세스를 하나 선택한 후 non-preemptively 실행한다. 예전에는 terminate 될 때만 CPU를 포기했지만, 지금은 I/O를 할 때도 CPU를 포기한다. 레디큐의 꼬리에 job이 들어가고 head에서 수행될 job이 pop 된다. Nachos에서는 FIFO가 실행된다.
FCFS Examples

FCFS Evaluation
- Non-Preemptive
- Response time : 프로세스의 수행 시간이 큰 분산을 가지고 있으면 느립니다. 수행 시간이 긴 프로세스가 먼저 도착하면, 뒤에 있는 수행 시간이 작은 프로세스는 오랫동안 기다려야 합니다. (convoy effect : 소요시간이 긴 프로세스가 먼저 도착해서 시간을 잡아먹고 있는 현상 -> Low CPU and I/O Utilization)
- Throughput : 특이점 없음
- Fairness : 소요 시간이 짧은 프로세스는 오래 기다려야 하는 상황이 억울할 것입니다.
- Starvation : 불가능
- Overhead : 복잡한 Scheduling이 없이 때문에 Minimal
Round-Robin
고정된 time slice를 가지고 있씁니다. 레디큐의 HEAD에서 실행될 프로세스를 고르고 최대 하나의 time slice만 수행시킵니다. 이 시간동안 해당 프로세스가 모두 종료되지 않았으면 레디큐의 뒤 쪽에 다시 넣습니다.
하나의 Time slice가 끝나기 전에 해당 프로세스의 작업이 모두 끝나면, 레디큐에서 다른 프로세스를 가져와서 최대 한 time slice만큼 실행시킵니다.
이를 위해서는 주기적인 간격으로 interrupt를 거는 H/W timer가 있어야 합니다. 이는 기본적을 FIFO의 구조를 갖는 것으로 생각할 수 있습ㄴ디ㅏ.
Round-Robin Example
Round-Robin Evaluation
- Preemptive
- Response time : 레디큐에 있는 전체 프로세스가 N개 있고 하나의 time slice의 길이가 q라고 할 때, 각자의 프로세스는 n*q만큼 기다려야 합니다. 앞에 있는 프로세스 에게는 좋습니다.
- Throughput : time slice에 따라서 달라집니다. time slice가 너무 짧으면 불필요한 context switching이 일어날 것입니다. 너무 길면 FCFS와 비슷한 Throughput이 될 것입니다.
- Fairness : I/O 프로세스가 불리해질 것입니다. 자꾸 I/O 중간에 끊기니까요
- Starvation : 불가능
- Overhead : Low
Shortest-Job-First or Shortest-Process-Next
가장 CPu burst가 조금 남은 프로세스를 다음 프로세스로 설정합니다. 그리고 그 프로세스를 non-preemptyively 실행합니다. 만약 두 개의 프로세스가 같은 길이만큼 남았다면 FCFS를 사용해서 tie인 경우를 해제합니다.
하지만 남은 시간일 얼마나 되는지 판단하는 것이 어렵다는 문제점이 있습니다. 과거의 경험에 따라서 이를 예측하는데, 현실에서는 불가능한 방법입니다.
Shortest-Job-First Example
Shortest-Job-First Evaluation
- Non-Preemptive
- Response time : 긴 프로세스는 자기보다 작은 프로세스가 모두 끝날 때까지 기다려야 합니다.
- Throughput : high
- Fairness : 소요 시간이 긴 프로세스는 오래 기다려야 하는 상황이 억울할 것입니다.
- Starvation : 소요 시간이 긴 프로세스가 말라 죽을 수 있습니다.
- Overhead : 높을 수 있습니다. 과거의 기록을 저정하고 예측하는데 어려움이 있을 수 있습니다.
Shortest-Remaining-Time (SRT)
SRT는 SJF의 preemptive 버전입니다.
가장 CPU burst가 조금 남은 프로세스를 고르고 preemptively 실행시킵니다.
- 고른 프로세스가 종료되거나,
- I/O를 하느라 Block 되거나,
- 새로운 프로세스가 생성되서 레디큐에 들어가거나,
- Block 되었던 다른 프로세스가 레디큐에 들어갈 때
preemptive 됩니다. 이 때 다른 프로세스를 고르는데 현재 프로세스의 CPU burst의 남은 양보다 더 작은 CPU burst를 가질 것으로 예상되는 프로세스를 고릅니다.
Shortest-Remaining-Time (SRT) Example
먼저 SJF입니다. SJF는 Non-preemptyively 실행되므로 먼저 시간 0에서는 P1만 있으므로 P1이 모두 실행됩니다. 8초가 되었을 때 P2,3,4이 모두 도착했고 이들 중 가장 조금 남은 P2를 Non-preemptively 실행시킵니다. 그리고 P4와 P3을 각각 실행시킵니다.
같은 조건에서 SRT의 경우 아래와 같습니다.
시간 0에서는 P1만 도착했으므로 일단 P1이 실행됩니다. 그리고 시간 1이 됐을 때 P1는 7이 남았고, 4가 남은 P2가 도착했으므로 P2가 실행됩니다. 매 초마다 P2가 제일 조금 남은 프로세스이므로 P2가 모두 실행되고 순서대로 같은 방법으로 P4 -> P1 -> P3가 실행됩니다.
Shortest-Remaining-Time (SRT) Evaluation
- Preemptive
- Response time : Good. 아마도 최적일 것입니다. 주어진 프로세스 집합에 대해서 평균적으로 기다리는 시간을 최소화 합니다.
- Throughput : high
- Fairness : 소요 시간이 긴 프로세스는 오래 기다려야 하는 상황이 억울할 것입니다. 중요한 것은 긴 프로세스도 결과적으로 짧은 프로세스가 된다는 점입니다.
- Starvation : 소요 시간이 긴 프로세스가 말라 죽을 수 있습니다.
- Overhead : 높을 수 있습니다. 비교하는데 어려움이 있을 수 있습니다.
Priority Scheduling
실제로 모든 O/S에서 사용하는 방법입니다.
각각의 프로세스마다 우선순위를 정해줍니다. 외부적으로 우선순위가 결정될 때에는 중요도, 돈, 정책에 따라서 결정됩니다. 내부적으로 결정될 때는 메모리 사용, 파일 요구정도, CPU 요구 정도에 따라서 결정됩니다. SJF은 우선순위 스케줄링입니다. 우선순위는 CPU burst 길이에 반비례했던 것입니다.
Priority Scheduling Evalutation
- 가장 우선순위가 높은 프로세스를 고르고 Preemtively든, non-Preemtively든 수행합니다. 둘 다 가능합니다.
- starvation : 낮은 우선순위를 가지는 프로세스는 말라 죽을 수 있습니다. 이를 해결하기 위한 방법으로
Aging이라는 것이 있습니다. 쉽게 말해서 너무 오래 기다리면 우선순위를 높혀주는 것을 말합니다.
Multilevel Queue Scheduling
각기 다른 우선순위를 가지는 여러 개의 레디큐를 만듭니다. 비어있지 않은 레디큐에서 가장 우선순위가 높은 프로세스를 선택해서 Preemtively든, non-Preemtively든 수행합니다. 새로운 프로세스를 영구적으로 특정한 큐에 계속 넣습니다. 우선순위가 높은 큐든 낮은 큐든 둘 다 가능합니다. 각각의 레디큐는 서로 스케줄링 정책을 가지고 있습니다.
예를 들어서 Preemptive, using timer한 환경에서 CPU 의 80%를 우선순위가 높은 레디큐를 Round-Robin으로 돌리고, 20%는 다른 레디큐를 FCFS으로 돌릴 수도 있습니다.
Multilevel Feedback Queue Scheduling (MFQS)
각기 다른 우선순위를 가지는 여러 개의 레디큐를 만듭니다. 비어있지 않은 레디큐에서 가장 우선순위가 높은 프로세스를 선택해서 Preemtively든, non-Preemtively든 수행합니다. 각각의 레디큐는 서로 스케줄링 정책을 가지고 있습니다. 스케줄러는 프로세스가 레디큐 사이를 이동할 수 있도록 합니다. 각각의 프로세스는 우선순위가 높은 레디큐에서 시작했다가 CPU burst를 수행하고나면 우선 순위가 낮은 레디큐로 옮겨집니다.
여기에서 Aging의 개념이 나옵니다. 오래된 프로세스를 더 높은 우선순위를 가지는 레디큐로 옮겨주는 것을 말합니다.
Feedback은 과거를 사용해서 미래를 예측하는 것을 말합니다. 스케줄러는 지금까지 지금까지 가장 적게 선택된 것을 더 좋아하는 경향이 있도록 설계합니다.
UNIX CPU Scheduling using MFQS
유닉스에서는 여러 개의 레디큐를 만들고 각각에 서로 다른 값을 할당합니다. 값이 작으면 더 높은 우선순위를 가지는 것입니다. Kernel 프로세스는 음수의 값을 가집니다. system process가 항상 원할 때 수행될 수 있도록 하기 위함입니다. 유저 프로세스는 양수의 값을 할당받습니다.
비어있지 않은 레디큐에서 가장 우선순위가 높은 프로세스를 선택해서 Preemtively 수행합니다. 각각의 큐는 Round-robin 정책에 따라서 수행됩니다.
프로세스를 큐 사이에서 이동할 수 있도록 하기도 합니다. 1초에 60번씩 clock ticks를 기록하고, Add clock ticks to priority value. 그리고 우선순위를 CPU 시간에 따른 공정한 정도와 비교해서 너무 많이 선택받지 못한 것을 우선순위를 올려줍니다.