
[ML][CNN] Chapter 0
Goal : CNN
Dropout
신경망의 학습 과정에서 파라미터의 동조화 현상으로 인해 overfitting이 발생하고 결과적으로 학습 효율이 떨어집니다. 이를 피하기 위한 regularization 기법으로써 dropout을 적용합니다.
Dropout의 효과는 주로 fully connected layer에 적용하여 효과를 얻었습니다.
max/mean pooling
pooling은 sub-sampling을 통해서 feature-map의 사이즈를 줄이고, 특징을 추출할 수 있도록 해줍니다.
mean pooling의 경우 depp CNN에서는 성는이 그리 좋지 못합니다. 왜냐하면 보통 활성함수로 ReLU를 많이 사용하는데 ReLU의 특성에 의해서 0이 많이 나오면 평균 연산에 의해서 값이 크게 줄어드는 문제가 발생했습니다. 만약 활성함수로 tanh를 사용하면 결과가 더 나빠질 가능성이 있는데 강한 양의 값과 강한 음의 값에 평균을 구하면 서로 상쇄되는 상황이 발생합니다.
max pooling의 경우 overfitting되는 문제가 발생합니다.
Stochastic pooling : training
Stochastic pooling은 pooling layer에 적용되는 regularization 방법입니다. 단순하게 max/mean activation을 선택하는 것이 아니라, dropout과 마찬가지로 확률 p에 따라서 적절한 activation을 선택합니다.
이 확률 p를 구하기 위해서 먼저 pooling window에 nomarlization(모든 activation의 합을 구하고 각각을 나눠주는 방식)을 적용합니다.
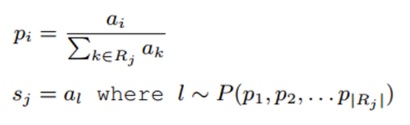
이렇게하면 window에 있는 모든 값이 선택될 확률을 갖게됩니다. back-propagation을 할 떄는 max-pooling 방식과 마찬가지로 선택된 activatino만 남기고 나머지는 전부 0으로 바꿔줍니다.
Probabillistic Weighting : testing
학습을 마치고 실제로 적용할 때도 Stochastic 방식을 사용하면 성능이 떨어지는 경향이 있기 때문에, 실제 test할 때는 아래와 같은 방식을 사용합니다.
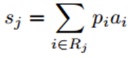
이 방법을 제안한 논문에서는 마치 dropout이 test시에 modeling averaging을 통해서 성능을 끌어올리는 것과 비슷한 효과를 얻을 수 있다고 주장합니다. 학습을 시킬 때는 확률에 기반한 sampling 방식을 통해 다양한 model을 학습하고, test 시에는 Probabillistic Weighting을 통해서 성능을 올리는 점은 dropout의 개념과 거의 유사합니다. pooling window의 크기를 n, poolin region의 갯수를 d라고 할 때, 가능한 모델의 수는 n^{d}가 되기 때문에 dropout을 수행할 때보다 훨씬 많은 모델 수가 가능합니다. 통상적인 pooling window의 크기가 4,9,16임을 고려할 때 모델의 수는 10^{4~6} 정도로 큰 조합이 가능합니다.