[DB] Chapter 9
5 minute read
교재
- 교재는 ‘Fundamentals of Database System’ 7th edition 구글링해서 찾기
- 6판에서 7판으로 개정되면서 big data 부분이 추가됨. 한글판은 6판까지만 있음
Chater 9 : Relational Database Design ER- and EER-to-Relation Mapping
- ER과 EER을 Ration으로 mapping하는 과정은 conceptual schema 설계 이후의 logical schema 설계의 과정이다.
- Relation mapping의 결과 relational database schema가 생성된다.
- conceptual schema로부터 RDB를 자동으로 생성해주는 CASE(Computer-Aided Software Engineering)을 사용한다.
Regular (strong) entity
- ER schema의 일반적인 E의 모든 attribute는 relation R을 생성할 때 모두 포함한다.
- 복합 attribute의 경우 각각의 요소를 simple attribute로 포함한다.
- fname과 lname은 포함하되, name이라는 복합 attribute는 추가하지 않는다.
- E가 가진 attribute 중 하나를 Primary Key로 설정한다.
- 만약 선택된 attribute가 복합 attribute라면, 이를 구성하는 simple attribute set이 모두 primary key가 된다.
Weak entity
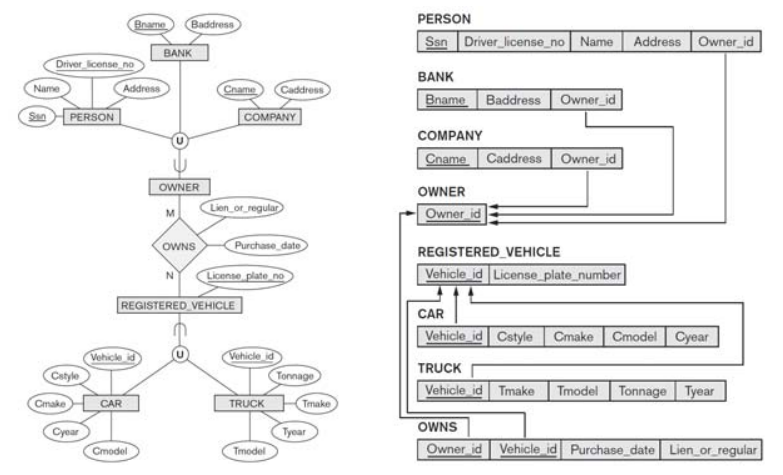
- weak entity가 포함하는 모든 attribute를 Relation R에 추가한다.
- weak entity의 partial key와 owner entity의 primary key를 더해 Reltion R의 PK가 된다.
- 이 때 Weak entity와 Owner Entity는 identifying relationship을 형성한다.
- Referential triggered action
- owner와 weak 사이에는 CASCADE option이 적용되고, UPDATE/DELETE operation에 대해서 CASCADE 하게 적용된다.
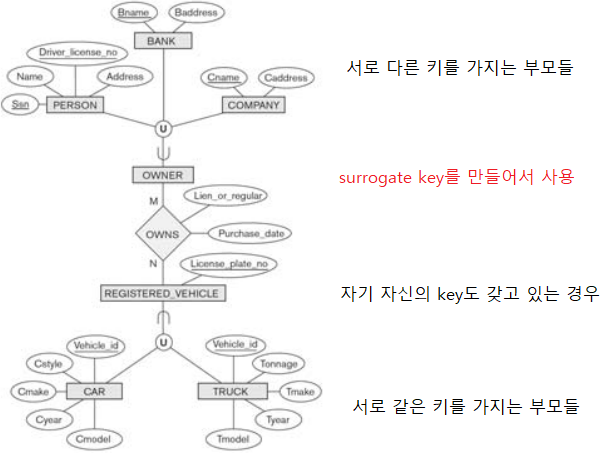
Binary 1:1 relationship
- relation S와 T가 1 : 1 관계를 형성할 때의 경우이다.
- 양 쪽 모두 partial participatin인 경우 S의 PK가 T의 FK가 될 수도 있고, 반대도 가능하다.
- 한 쪽이 total participation인 경우 partial participation인 relation의 PK를 total 쪽의 FK로 추가한다.
- 예를 들어 S 는 TOTAL 이고 T는 PARTIAL이다.
- S는 반드시 T를 가지고, T는 S를 가지지 않을 수 있다.
- T의 PK를 S의 FK로 하면 T의 PK attribute를 항상 값을 갖는다.
- 하지만 S의 PK를 T의 FK로 하면 T는 S를 가지지 않을 수 있기 때문에 NULL 값이 발생할 수 있다.
- 양쪽이 total participation인 경우 S와 T를 하나의 reltaion으로 변경하는 것을 고려한다.
Binary 1:N relationship
- relation S와 T가 1 : N 관계를 형성할 때의 경우이다.
- 1에 해당하는 relation의 PK를 N쪽의 FK로 설정한다.
- 만약 N쪽의 PK를 1쪽의 FK로 적으면, N개 중 어떤 것에 대한 FK인지 알 수 없다.
- 1쪽을 parent, N쪽을 child라고 생각할 때, parent의 PK를 child에서 FK로 가지고 있는다.
- Relationship에 attribute가 있는 경우 역시 N쪽에 추가한다.
- Relationship의 attribute는 PK를 가리키는 FK를 추가하는 쪽에 따라가는 것으로 생각하자.
Binary M:N relationship
- relation S와 W가 N : N 관계를 형성할 때의 경우이다.
- PK와 FK로는 N : N 관계를 표현할 수 없다.
- 따라서 R: S <–> W에 대해서, R을 표현하는 relation T를 생성해주어야 한다.
- 이 때 S를 relationship relation이라고 부른다.
- erwin 에서는 associative entity로 표현되던 개념이다.
- relationship relation의 경우 항상 PK가 복합키이다.
- S가 표현하는 relationship에 참여하는 relation들의 PK set을 PK로 갖는다.
- 따라서 UPDATE/DELETE 시에 CASCADE 하게 동작한다.
- relationship에 attribute가 있다면 S에 추가한다.
- erwin의 LOGICAL MODEL에서는 relationship의 attribute를 표현할 수 없었다.
- erwin의 PHYSICAL MODEL에서는 relationship의 attribute를 표현할 수 있다.
- 필요에 따라서 1 : N의 경우에도 relationship relation S을 정의할 수 있다.
- 이 때는 N쪽의 PK만 S의 pk로 설정하면 된다.
- 양쪽 다 PARTIAL 참여이고, 아주 희소한 관계인 경우 NULL을 줄이기 위해서 사용한다.
- 필요에 따라서 1 : 1의 경우에도 relationship relation S을 정의할 수 있다.
- 이 때는 양 쪽 중 하나의 relation의 PK만 S의 pk로 설정하면 된다.
- 양쪽 다 PARTIAL 참여이고, 아주 희소한 관계인 경우 NULL을 줄이기 위해서 사용한다.
- 남 1만명 : 여 1만명의 경우 결혼한 커플이 10커플밖에 없다면, 배우자 attribute를 남/여에 추가하면 비효율적이다.
- married couple relation을 추가해서 여기에 배우자 attribute를 추가하는 것이 더 적합할 것이다.
Multivalued attribute
- RDB에는 multivalued를 표현하는 방법이 없다. 따라서 이를 위한 relation이 별도로 생성되어야 한다.
- 예를 들어 어떤 사람이 가지고 있는 자동차가 여러개인 경우, PERSON-HAVE-CAR relation을 만든다.
- 그리고 이 relation의 PK는 ‘사람의 PK’와 car attribute 두 개 만을 포함하도록 구성한다.
N-ary relationship type
- N개의 entity에 대한 관계를 나타내는 relation S를 정의한다.
- 각 entity의 PK를 S의 FK로 설정한다.
- S의 PK는 모든 FK의 집합으로 구성된다.
- 단, N개의 entity 중 cardinality가 1인 entity의 PK는 S의 PK를 구성하는 FK set의 원소로 포함하지 않아도 된다.
Relationship Type in RDB
- ER schema와 달리 relation schema에서는 relation type(1:1, 1:N etc)등이 포함되지 않는다.
- 다만 PK 와 FK 쌍만 구분할 수 있다.
- instance의 예제를 보면 relation type을 추론할 수 있게 된다.
- 만약 relation S에 속한 attribute A와 relation T에 속한 attribute B가 PK,FK 관계에 있을 때, 이들에 대해서 EQUIJOIN 또는 NATURAL JOIN을 하면 모든 관련된 tuple들의 조합을 얻을 수 있다.
- 다만, 1:1 또는 1:N 상황에서는 SINGEL JOIN으로 결과를 얻을 수 있는 반면,
- N:M 관계에서는 TWO JOINTS가 필요하고
- N-ary 관계에서는 N-1 JOINTS가 필요하다.
- 만약 FK, PK 쌍이 아닌 attribute에 대해서 JOIN을 하면 spurious(invalid)한 data가 도출된다.
- basic relation algebra는 NEST(relation이 value로 저장될 수 있는 경우) or COMPRESS operation을 지원하지 않는다. 따라서 multivalued attribute의 경우 독립적인 reltation을 구성한다.
RDB Specialization or Generalization
| 개념 |
의미 |
| Attrs(R) |
relation R의 attributes |
| PK(R) |
reltion R의 primary key |
Option 8A
- total/partial, disjoint/overlapping 모든 경우에 사용할 수 있는 방법
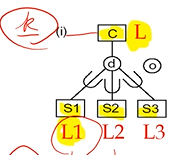
- Create a relation L for C
- 부모 entity에 대해서는 자신의 attribute와 key만을 포함한다.
- Attrs(L) = {k, a1,…,an} and PK(L) = k
- For each subclass Si, 1≤ i ≤ m, create a relation Li
- 자식 entity의 경우 자신의 attribute와 key + 부모의 key attrubte를 갖는다.
- Attrs(Li) = {k} ∪ {attributes of Si}
- PK(Li) = k
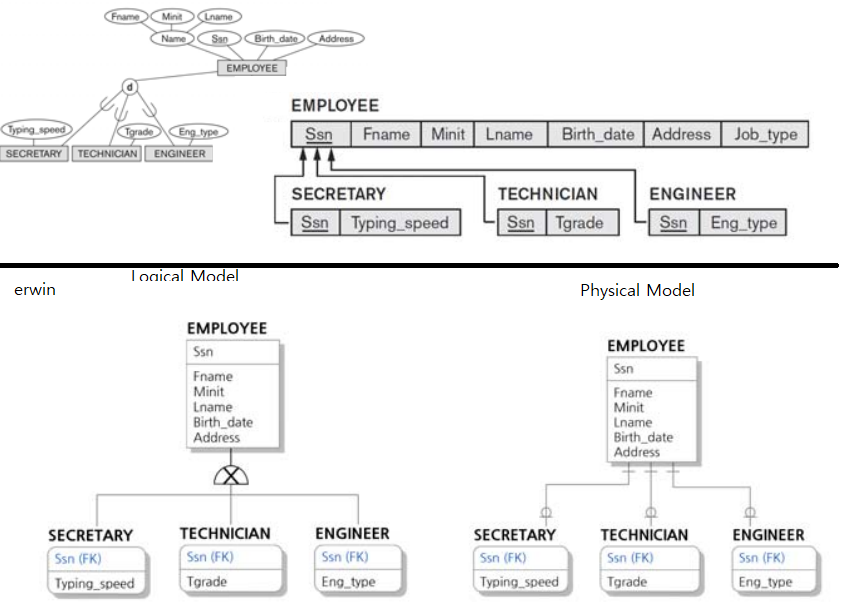
| erwin에서 제공하는 Transformation(Logical to Physical) |
의미 |
| Supertype-Subtype RollUp |
아래에서 업급하는 8C 방법 |
| Supertype-Subtype RollDown |
아래에서 언급하는 8B 방법 |
| Resolve to Supertype Subtype identity |
위 그림의 8A 방법. 부모 자식 모두 각자의 relation으로 표현된다. |
- inclusion dependency
- 부모의 key 없이 자식의 key가 존재할 수 없다.
- π : key의 집합
- π(자식entity) ⊆ π(부모entity)
- π(Li) ⊆ π(L)
Option 8B
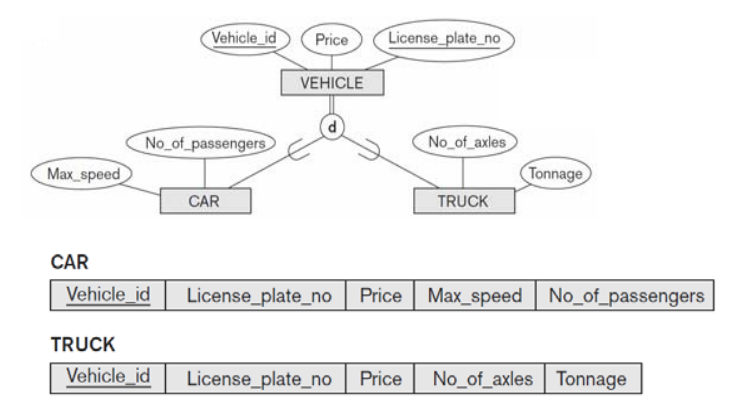
- 부모 relation은 생성하지 않음
- disjoint이고 total인 경우 잘 적용된다.
- 만약 total이 아닌 경우(CAR, TRUCK이 아닌 VEHICLE이 있는 경우) : 정보를 표현할 수 없음
- 만약 disjoint이 아닌 경우(CAR 이면서 TRUCK 인 경우) : 동일한 정보가 여러 subtype에 중복되어서 나오는 문제가 있음
- 따라서 VEHICLE 전체의 구조를 보고 싶으면 OUTERJOIN(구조가 서로 다른 table을 JOIN) 또는 FULL OUTERJOIN을 CAR와 TRUCK에 적용해야 한다.
- Create a relation Li for each subclass Si, 1 ≤ i ≤ m,
- Attrs(Li) = { attributes of Si } ∪ {k, a1,…., an}
- PK(Li) = k
Option 8C
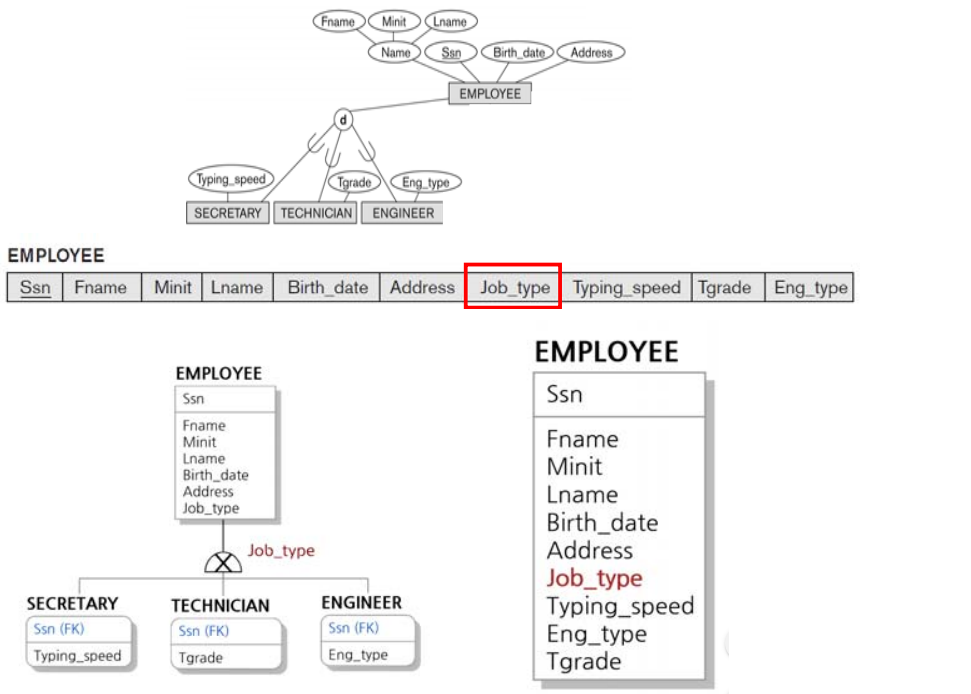
- 부모 relation만 생성한다.
- Create a single relation L
- Attrs(L) = {k,a1,…,an} ∪ {attributes of S1} ∪ . .∪ {attributes of Sm} ∪ { t }
- t = type (or discriminating) attribute that indicates the subclass to which each tuple belongs, if any.
- PK(L) = k
- t를 추가하기 때문에 disjoint인 상황에서만 사용할 수 있는 방법
- subtype 중 하나에만 속하기 때문에 굉장히 많은 NULL 값이 생성될 수 있는 방법
Option 8D
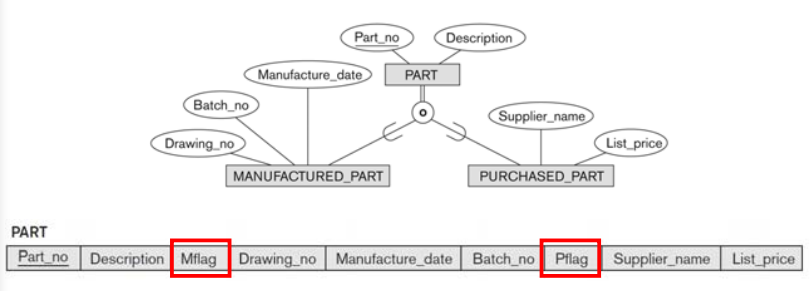
- subclass들이 overlap되는 경우 사용할 수 있는 방식
- Create a single relation schema L
- Attrs(L)= {k,a1,…,an} ∪ {attributes of S1} ∪ . . . ∪ {attributes of Sm} ∪ {t1, t2, …, tm}
- PK(L) =k
- each ti, 1≤ i ≤ m, is a Boolean attribute indicating whether a tuple belongs to subclass Si,
- subclass의 attribute가 많으면 추천하지 않는 방식
- subclass의 attribute가 별로 없고, JOIN이 자주 사용되는 경우.(저장공간과 성능 사이의 상충관계)
Mapping of Shared Subclasses
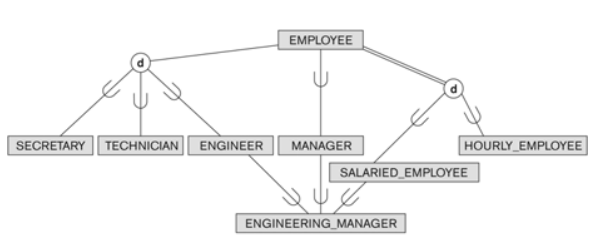
- 부모의 key attribute가 같은 경우 super class로 표현가능하다.
- 부모의 key attribute가 다른 경우 category로 표현가능하다.