
[DB] Chapter 2 Database System Concepts and Architecture
교재
- 교재는 ‘Fundamentals of Database System’ 7th edition 구글링해서 찾기
- 6판에서 7판으로 개정되면서 big data 부분이 추가됨. 한글판은 6판까지만 있음
Chapter 2 Database System Concepts and Architecture
Data Model = (S, O, C)
| 개념 | 의미 |
|---|---|
| 데이터 추상화 | 데이터가 어떻게 저장되었는지는 숨기고, 사용자에게 conceptual view를 제공한다. |
| Data Model | DB의 구조를 묘사하기 위한 개념들. 그리고 DB가 따라야하는 특정한 제약들. |
Data Model은 데이터 추상화를 위해서 필요한 수단들을 제공한다. | Data Model의 수단들 | 의미 | |:——–|:——–| |structure|data types, relationships, constraints| |a set of operations| querying, update를 위한 기능들| |constraints| 제약사항|
database structure를 묘사하기 위해서 사용하는 개념의 종류에 따른 data model 분류
| types of concepts | 같은 뜻 | 의미 |
|---|---|---|
| High Level data model | Conceptual data model | entity, attribute, relationship의 개념 사용 |
| Representational data model | Implementation data model | 아래에 설명 |
| Low Level data model | Physical data model | recored format, recored ordering, access path의 개념 사용 |
| types of concepts | 활용 |
|---|---|
| High Level data model | database designer들이 CS 비전공자와 요구사항을 확인할 때 사용. 일반적으로 사용하는 모델은 ER Model |
| Representational data model | database의 논리적인 부분을 나타내기 위해서만 사용됨. 물리적인 부분은 나타내지 않음. database의 design 파트에만 집중할 수 있도록 함. 코드 레벨의 구현 관점에서 사용되는 데이터 모델. |
| Low Level data model | 데이터가 물리적으로 저장되는 format과 file에 대한 정보 |
Representatinoal data model의 특성
- CDM 과 PDM의 사이의 개념을 제공
recored based data model로서 전통적인 상업 DBMS에 가장 많이 사용됨- Relational Data Model, Network and hierarchical Model, OO Models .. etc
Schemas, Instances, Database State
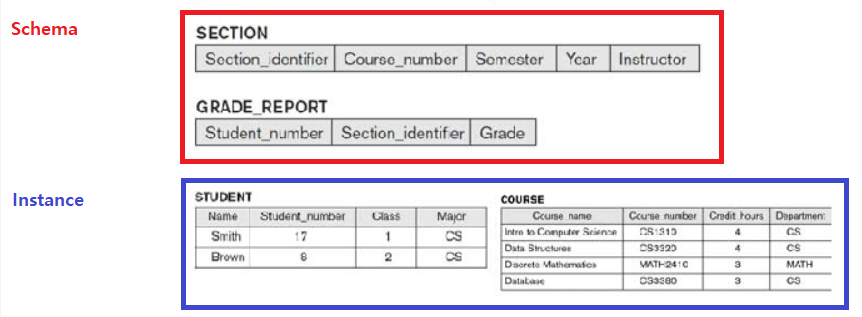
| 개념 | 의미 |
|---|---|
| Database schema | 데이터베이스를 묘사하는 것. system catalog에 저장된 meta-data. Intension이라고도 부름. |
| Database state | 특정 시간에 database에 저장된 data. Extension이라고도 부름. DB의 instance. |
| valid state | shcema의 structure 와 constraints를 만족하는 상태. |
| schema evolution | schema에 적용되어야 하는 변화들 |
- 특정 database에 대해서 각각의 schema 구조는 현재의 instances를 가지고 있다.
- database는 특정 시점에 대해 current state를 가지고 있다.
- DBMS는 모든 state가 valid state이도록 보장할 의무가 있다.
- 전체적인 흐름은 다음과 같다.
- 현실 세계를 반영해서 data model을 생성한다. 이 때 S,O,C를 포함해야 한다.
- data model은 DBMS에 structure를 제공한다.
- database의 schema는 현실 세계를 인지한 방법을 표현한다.
- shema는 instance가 valid state를 가질 수 있도록 규칙을 제공한다.
- database의 instance는 특정 현실 세계를 묘사한다.
The Three-Schema Architecture
3단계-스키마 아키텍처의 목적은 물리적 데이터베이스로부터 사용자 응용들을 분리하는 것이다. 3단계-스키마 아키텍처는 데이터 독립성의 개념을 설명하기 위해 사용될 수 있다.
| level | shema | view | 의미 |
|---|---|---|---|
| External level | external schema | Individual User View | 특정 유저 그룹이 관심있는 영역만을 묘사하고 나머지는 숨김. |
| Conceptual level | conceptual schema | Community(Organization) User View | 사용자 커뮤니티를 위한 전체 DB의 구조를 묘사. entity, data types, relationships, user operations, constraints를 묘사하는데 집중 |
| internal level | internal schema | Storage View | database의 물리적인 저장 구조를 묘사 |
| level | Implementation example | |
|---|---|---|
| External Schema | Course info(cid:int,cname:string) , student info(id:int. name:string | ) |
| Conceptual Shema | Students(id: int, name: string, login: string, age: integer) , Courses(id: int, cname.string, credits:integer) , Enrolled(id: int, grade:string) | |
| Physical Schema | Relations stored as unordered files. Index on the first column of Students. |
Data Independence
한 단계 위의 레벨의 schema의 변경없이 특정 단계의 schema를 변화할 수 있는 가능성
- Physical data independence : conceptual level을 internal/physical level로부터 독립할 수 있는 가능성. 물리적인 구조를 명시할 필요없이 논리적인 묘사를 제공할 수 있게 됨.
- 새로운 하드드라이브를 사용해도 논리적인 구조를 바꾸지 않아도 됨.
- 파일 시스템의 로직이 바뀌어도 논리적인 구조를 바꾸지 않아도 됨.
- 새로운 데이터 구조를 사용해도 논리적인 구조를 바꾸지 않아도 됨.
- access method를 바꾸어도 논리적인 구조를 바꾸지 않아도 됨.
- indexes를 바꾸어도 논리적인 구조를 바꾸지 않아도 됨.
- comparison technique나 hash algorithm을 바꾸어도 논리적인 구조를 바꾸지 않아도 됨.
- Logical data independence : external view, api, program을 conceptual schema로부터 독립할 수 있는 가능성.
- entity,attribute,relationship의 추가,수정,삭제의 논리를 바꾸어도 external view는 바뀌지 않음.
- record를 merge하고 divide해도 external view는 바뀌지 않음.
Protection
보호(protection)는 하드웨어 또는 소프트웨어 오동작(또는 붕괴)으로부터 시스템을 보호하는 기능(system protection )과 권한이 없는 또는 악의적인 접근을 하려는 보안 위협으로부터 보호하는 기능(security protection)을 포함한다.
이상 ppt 정리 끝.
Data Model = ( S,O,C ) : Structure & Operations & Constraints제약조건
- a collection of concepts to describe the structure of a DB and certain constraints that the DB sould obey
- provides t he necessary means to achieve the abstraction
- structure & operations
- structure : data types, relationships and !!constraints제약조건!!
- a set of basic operations for specifying retrievals and updates
- 요즘엔 C와 S를 합쳐서 S와 O 두 개로 얘기하기도 한다.
We can catagorize them according to the types of concepts they use to describe the database structure
- High-level or conceptual data models
- use concepts such as entity, attribute, relationship
- Representational ( or implementation) data models
- 사람이 이해하기도, 구현하기도 편한 중간 형태
- provide concepts between CDM and PDM (Conceptual Data Model / Physical Data Model)
- record-based data models : used most frequently in traditional commercial DBMSs
- relational data model, network and hierarchical models, OO models …
- Low-level or physical data models
- 데이터가 컴퓨터애 어덯게 저장되는가?
- record formats, record orderings, and access paths
- 데이터가 컴퓨터애 어덯게 저장되는가?
- entity를 record로 표현하고 실제로는 format으로 구현되는 흐름이다.
Database Schemas
- the description of a database - meta-data stored in a system catalog
- 어려운 말로는 intension이라고 한다. 한국어로는 내포
- Schema diagram
Database state or snapshot
- the data in the database at a particular moment in time
- extension외연
- the current set of occuences or instances in the DB
Schenasm Instances, and Database State
- Define : 정의하는 것
- populate : 처음의 데이터를 넣는다. -> initial state -> update -> new state
- At any point in time, the database has a current state
- The DBMS는 이 안에 들어있는 데이터는 원래 정해진 조건에 부합되는 데이터들!
- Valid state is a state that satisfies the structure and constraints specified in the schema
- Schema Evolution : changes need to be applied to the schema
2.1 Data Models, Schemas, and Instances
Data abstraction generally refers to the suppression of details of data organization and storage, and the highlighting of the essential features for an improved understanding of data. One of the main characteristics of the database approach is to support data abstraction so that different users can perceive data at their preferred level of detail.
- hiding details of data storage that are not needed by most database users.
A data model a collection of concepts that can be used to describe the structure of a database—provides the necessary means to achieve this abstraction.
By structure of a database we mean the data types, relationships, and constraints that apply to the data. Most data models also include a set of basic operations for specifying retrievals and updates on the database.
2.1.1 Categories of Data Models
High-level or conceptual data models provide concepts that are close to the way many users perceive data, whereas low-level or physical data models provide concepts that describe the details of how data is stored on the computer storage media, typically magnetic disks.
Conceptual data models use concepts such as entities, attributes, and relationships.
- An
entityrepresents a real-world object or concept, such as an employee or a project from the miniworld that is described in the database. - An
attributerepresents some property of interest that further describes an entity, such as the employee’s name or salary. relationshipamong two or more entities represents an association among the entities, for example, a works-on relationship between an employee and a project.
2.1.2 Schemas, Instances, and Database State
In a data model, it is important to distinguish between the description of the database and the database itself. The description of a database is called the database schema, which is specified during database design and is not expected to change frequently.6 Most data models have certain conventions for displaying schemas as diagrams.7 A displayed schema is called a schema diagram.
We call each object in the schema—such as STUDENT or COURSE a schema construct.
The data in the database at a particular moment in time is called a database state or snapshot. It is also called the current set of occurrences or instances in the database.
The distinction between database schema and database state is very important. When we define a new database, we specify its database schema only to the DBMS. At this point, the corresponding database state is the empty state with no data. We get the initial state of the database when the database is first populated or loaded with the initial data.
At any point in time, the database has a current state.8 The DBMS is partly responsible for ensuring that every state of the database is a valid state—that is, a state that satisfies the structure and constraints specified in the schema. Hence, specifying a correct schema to the DBMS is extremely important and the schema must be designed with utmost care. The DBMS stores the descriptions of the schema constructs and constraints—also called the meta-data—in the DBMS catalog so that DBMS software can refer to the schema whenever it needs to. The schema is sometimes called the intension, and a database state is called an extension of the schema.
2.2 Three-Schema Architecture and Data Independence
Three of the four important characteristics of the database approach, listed in Section 1.3, are
- (1) use of a catalog to store the database description (schema) so as to make it self-describing,
- (2) insulation of programs and data (program-data and program-operation independence), and
- (3) support of multiple user views.
In this section we specify an architecture for database systems, called the three-schema architecture, that was proposed to help achieve and visualize these characteristics. Then we discuss further the concept of data independence.
2.2.1 The Three-Schema Architecture
- The internal level has an internal schema, which describes the physical storage structure of the database. The internal schema uses a physical data model and describes the complete details of data storage and access paths for the database.
- The conceptual level has a conceptual schema, which describes the structure of the whole database for a community of users. The conceptual schema hides the details of physical storage structures and concentrates on describing enties, data types, relationships, user operations, and constraints.
- The external or view level includes a number of external schemas or user views. Each external schema describes the part of the database that a particular user group is interested in and hides the rest of the database from that user group.
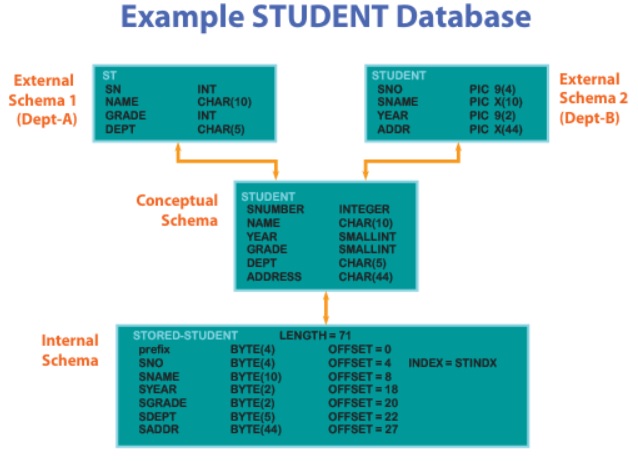
Schema가 있을 때 데이터는 DISK에 물리적 레벨에서 저장되어있는 상태로만 있다. 유저입장에서는 External View만 보고 사용한다. 각 유저는 자신의 schema level을 보고 파악한다. DBMS는 3개의 Schema에 대한 명령을 변환시켜주어서 데이터를 검색하고 검색한 데이터는 internal한 form으로 나온다. 이를 Conceptual -> external 형태로 변환해서 user에게 보여준다.
유저는 ‘SN’을 검색했지만 Conceptual은 ‘SNUMBER’를 검색하는 명령으로 바꿔준다. DBMS는 ‘STORED-STUDENT’라는 BOX 안에 SNO라는 이름으로 4BYTE OFFSET 4바이트를 가지고 있다고 알고 이를 Conceptual scheme에게 보내준다. conceptual은 이를 integer로 바꾸고 C 스타일로 바꿔서 유저에게 보여준다.
위와 같은 명령을 바꾸고, 검색 결과를 바꿔서 전달하는 과정을 mapping이라고 한다. 이러한 과정은 시간도 오래걸리고 비용이 크다. 이렇게 3단계 Schema가 도입된 이유는 데이터의 독립성을 위해서이다. 어떤 데이터가 수정이 되었을 때 위의 level에는 영향을 주지 않기 위함이다. 어떤 특정레벨에서 Schema가 바뀌면 상위 사용자들에게는 영향을 주지 않는다.
2.2.2 Data Independence
conceptual schema가 바뀌어도 external schema에는 영향을 주지 않는다. 이것이 어떻게 가능하냐?? view definition과 mapping만 변하면 된다?
The three-schema architecture can be used to further explain the concept of data independence, which can be defined as the capacity to change the schema at one level of a database system without having to change the schema at the next higher level. We can define two types of data independence:
Logical data independenceis the capacity to change the conceptual schema without having to change external schemas or application programs. We may change the conceptual schema to expand the database (by adding a record type or data item), to change constraints, or to reduce the database (by removing a record type or data item). In the last case, external schemas that refer only to the remaining data should not be affected. mapping 시키는 방법은 DBMS의 책임이고 user의 책임이다. user는 몰라도 된다. 이러한 것을 논리적 데이터 독립성이라 한다.Physical data independenceis the capacity to change the internal schemawithout having to change the conceptual schema. Hence, the external sche mas need not be changed as well. Changes to the internal schema may be needed because some physical files were reorganized. interal schema가 바뀌어도 conceptual/external schemal에 영향을 주지 않는다. 원래 있던 데이터가 똑같이 들어있기만 하면, 구조가 바뀌어도 윗단에 영향을 주지 않는다. mapping만 바뀌면 된다. 실제로는LDI,PDI를 지나고 mapping하면서 시간 손실이 많이 일어난다. 그래서 실제로는 external과 conceputla 두 schema를 합쳐서 제공한다.
2.3 Database Languages and Interfaces
In Section 1.4 we discussed the variety of users supported by a DBMS. The DBMS must provide appropriate languages and interfaces for each category of users. In this section we discuss the types of languages and interfaces provided by a DBMS and the user categories targeted by each interface.
2.3.1 DBMS Languages
Once the design of a database is completed and a DBMS is chosen to implement the database, the first step is to specify conceptual and internal schemas for the database and any mappings between the two. In many DBMSs where no strict separation of levels is maintained, one language, called the data definition language (DDL), is used by the DBA and by database designers to define both schemas. The DBMS will have a DDL compiler whose function is to process DDL statements in order to identify descriptions of the schema constructs and to store the schema description in the DBMS catalog.
일단 DB의 디자인이 완성되면 DBMS는 이를 implement해야한다. 첫 번째로는 conceptual schemas와 internal schema를 명시화하고 이 둘을 연결해주는 mapping을 명시해야한다. 구분되는 레벨이 없는 많은 DBMS에서는 DDL이라고 불리는 단 하나의 언어만 사용된다. 이 언어는 DBA와 DB 디자이너들에 의해서 사용된다.
In DBMSs where a clear separation is maintained between the conceptual and internal levels, the DDL is used to specify the conceptual schema only. Another language, the storage definition language (SDL), is used to specify the internal schema. The mappings between the two schemas may be specified in either one of these languages.
반대로 conceptual and internal levels 사이에 분명한 구분이 있는 DBSM에서는 DDL은 오직 conceptual schema에만 사용된다. 다른 언어인 SDL이 interaml schema를 위해서 사용된다. 이 둘 사이의 mapping은 이 둘 중 하나의 언어로 명시될 수 있다.
In most relational DBMSs today, there is no specific language that performs the role of SDL. Instead, the internal schema is specified by a combination of functions, parameters, and specifications related to storage of files. These permit the DBA staff to control indexing choices and mapping of data to storage.
많은 대부분의 DBMS에서는 SDL의 역할을 하는 특정한 언어가 존재하지 않는다. 대신에 internal schema는 함수, 파라미터 그리고 파일과 관련된 specifiation들에 의해서 명시된다.
For a true three-schema architecture, we would need a third language, the view definition language (VDL), to specify user views and their mappings to the conceptual schema, but in most DBMSs the DDL is used to define both conceptual and external schemas. In relational DBMSs, SQL is used in the role of VDL to define user or application views as results of predefined queries (see Chapters 6 and 7).
3가지 schema를 가지고 있는 구조에서는 3번째의 언어가 필요하고 이를 VDL이라고 부른다. 이것은 user view를 명시하고 user와 conceptual schema 사이의 맵핑을 명시한다. 하지만 대부분의 DBMS에서는 DDL은 conceptual과 external schema를 모두 명시한다. 관계형 DBMS에서는 SQL이 VDL의 역할을 한다.
Once the database schemas are compiled and the database is populated with data, users must have some means to manipulate the database. Typical manipulations include retrieval, insertion, deletion, and modification of the data. The DBMS provides a set of operations or a language called the data manipulation language (DML) for these purposes.
There are two main types of DMLs.
A high-level or nonprocedural DML: can be used on its own홀로 to specify complex database operations concisely. Many DBMSs allow high-level DML statements either to be entered interactively from a display monitor or terminal or to be embedded in a general-purpose programming language. In the latter case, DML statements must be identified within the program so that they can be extracted by a precompiler and processed by the DBMS. High-level DMLs, such as SQL, can specify and retrieve many records in a single DML statement; therefore, they are called set-at-a-time or set-oriented DMLs. (서울출신 모두 일어서, 한 번에 하나의 집합을 처리.) A query in a high-level DML often specifies which data to retrieve rather than how to retrieve it; therefore, such languages are also calleddeclarative.택시 손님이 목적지 가는 경로를 알려준다?A low- level or procedural DMLmust be embedded in a general-purpose programming language. This type of DML typically retrieves individual records or objects from the database and processes each separately. Therefore, it needs to use programming language constructs, such as looping, to retrieve and process each record froma set of records. for문을 돌면서 한 번에 하나의 데이터를 처리할 수 있다. 너 서울 출신이야?
Whenever DML commands, whether high level or low level, are embedded in a general-purpose programming language, that language is called the host language and the DML is called the data sublanguage.10 On the other hand, a high-levelDML used in a standalone interactive manner is called a query language. In gen- eral, both retrieval and update commands of a high-level DML may be used inter-actively and are hence considered part of the query language.
- DML :
- A high-level or nonprocedural DMl :
- declarative languages : .
- set-at-a-time or set-oriented DMLs : - A low-level or procedural DML
- recored-at-a-time? :
-
QUery language :
- Data sublanguage
- host language
- SQL
- a comprehensive integrated language
- a combination of DDL, VDL, and DML, as well as statements for constracint specificatino and schema evolution
2.3.2 DBMS Interfaces
I/O에 관한 부분은 OS의 기능을 사용한다. buffer management는 많은 DBMS들이 그들 자신의 modeul을 사용한다. 디스크에서 읽고 쓰고 하는 명령을 Stored data manager에서 전담한다.
2.4 The Database System Environment
The database and the DBMS catalog are usually stored on disk. Access to the disk is controlled primarily by the operating system (OS), which schedules disk read/write. Many DBMSs have their own buffer management module to sched- ule disk read/write, because management of buffer storage has a considerable effect on performance. Reducing disk read/write improves performance consid- erably. A higher-level stored data manager module of the DBMS controls access to DBMS information that is stored on disk, whether it is part of the database or the catalog.
Casual users and persons with occasional need for information from the database interact using the interactive query interface in Figure 2.3. We have not explicitly shown any menu-based or form-based or mobile interactions that are typically used to generate the interactive query automatically or to access canned transactions. These queries are parsed and validated for correctness of the query syntax, the names of files and data elements, and so on by a query compiler that compiles them into an internal form.
This internal query is subjected to query optimization (discussed in Chapters 18 and 19). Among other things, the query optimizer is concerned with the rearrangement and possible reordering of operations, elimina- tion of redundancies, and use of efficient search algorithms during execution. It consults the system catalog for statistical and other physical information about the stored data and generates executable code that performs the necessary operations for the query and makes calls on the runtime processor.
Application programmers write programs in host languages such as Java, C, or C++ that are submitted to a precompiler. 하나의 프로그램에 DB SQL명령과 C 명령이 같이 들어있으면 어렵다. precompiler를 지나면 하나는 C코드만 빼고 하나느 SQL 코드를 포함하는 별도의 프로그램으로 나눈다. 그리고 원래의 형태를 함수를 호출하는 부분으로 바꾼다. The precompiler extracts DML commands from an application program written in a host programming language. These com- mands are sent to the DML compiler for compilation into object code for database access. The rest of the program is sent to the host language compiler. The object codes for the DML commands and the rest of the program are linked, forming a canned transaction whose executable code includes calls to the runtime database processor. It is also becoming increasingly common to use scripting languages such as PHP and Python to write database programs.
- Runtime database processor
- handles database access at run time;
- Query Compiler + Query Optimizer효율적으로 질의를 하도록 도와줌 : Query Processor 라고도 부름..
2.4.2 Database System Utilities
- 설명 간단히 하고 넘어감
In addition to possessing the software modules just described, most DBMSs have database utilities that help the DBA manage the database system. Common utili- ties have the following types of functions:
Loading. A loading utility is used to load existing data files—such as text
files or sequential files—into the database. Usually, the current (source) for-
mat of the data file and the desired (target) database file structure are speci-
fied to the utility, which then automatically reformats the data and stores it
in the database. With the proliferation of DBMSs, transferring data from
one DBMS to another is becoming common in many organizations. Some
vendors offer conversion tools that generate the appropriate loading pro-
grams, given the existing source and target database storage descriptions
(internal schemas).
2.5 Centralized and Client/Server Architectures for DBMSs
2.5.1 Centralized DBMSs Architecture
하나의 컴퓨터 안에 DBMS, OS 모두 깔려있고 사용자는 이것을 사용하기만 하는 것을 Centrialized라고 함. 모든 유저는 단말기를 사용해서 중앙의 DBMS를 사용하는 것.
2.5.2 Basic Client/Server Architectures
서버들이 수행하는 역할을, 하나의 서버가 하나의 역할만 하도록 구분하게 되었다. File Servers, Printer Servers, Web Servers, DB Servers. Client와 각각의 역할을 하는 서버들을 network를 통해서 연결 : Two tier 아키텍쳐. 각 서버마다 클라이언트, DB, 서버 역할을 할 수도 안할 수도 있다. 최소 한 개의 역할은 하는 것 같다.
2.5.3 Two-Tier Client/Server Architectures for DBMSs
In relational database management systems (RDBMSs), many of which started as centralized systems, the system components that were first moved to the client side were the user interface and application programs. Because SQL (see Chapters 6 and 7) provided a standard language for RDBMSs, this created a logical dividing point between client and server. Hence, the query and transaction functionality related to SQL processing remained on the server side. In such an architecture, the server is often called a query server or transaction server because it provides these two functionalities. In an RDBMS, the server is also often called an SQL server.
Logical two-tire client/server architecture
택시타고 일 끝날 때까지 택시 기다리게 하기.
Logical two-tire client/server architecture를 사용하다보면 각 서버마다 서로 다른 종류의 DBMS를 사용할 수도 있다. ORACLE/DB2/MSSQL 등등 사용자가 특정 서버의 DB에 연결하기 위해서는 서로 다른 환경을 조작할 수 있어야 한다. 이런 문제점을 해결하기 위해서 중간에 표준 interface를 추가한다. 사용자는 표준 interface만 알고 요청을 날리고, 이 interface가 oracle/DB2/MSSQL 등의 명령어로 convertion해서 query를 날려줄 수 있다. 사용자는 표준 interface만 알고있으면 되는 것이다. 이 표준 interface가 ODBC이다.
- ODBC : 모든 유저는 ODBC로 access하면 된다. DB는 자신의 요청을 ODBC API로 받아와서 처리해준다. C/C++를 위한 환경
- JDBC : Java를 지원하는 ODBC의 기능 지원
2.5.4 Three-Tier and n-Tier Architectures for Web Applications
일 끝나고 택시 다시 부르고 왔다 갔다 시간만 돈 내기.
수강신청할 때 DB에 동시에 접근할 수 있는 인원이 3명일 때, 3명이 각자의 권한을 놓을 때까지 나머지 사람들은 queue에서 기다리고 있어야 한다. 그런데 수강신청히 1초에 3000명 정도 로그인을 하는데 우리 학교 DB는 16~32명이 DB에 동시에 접근할 수 있다. 나머지는 모두 waiting을 하고 있다. 16~32명도 화면 띄우고 고민하다가 마지막 0.1초에만 DB에 직접 Access를 한다. 이를 해결하기 위해서 수강신청을 하는 프로그램과 DB에 Access 접근하는 프로그램을 분리한다. 수강신청을 하는 동안에는 DB를 Access하는 권한을 주지 않는다. 따라서 많은 유저가 수강신청 페이지에 Login을 할 수 있는 것이다.
어떻게 3가지로 나눠지는지 이름 외우기
client 입장에서는 GUI로 Web interface를 볼 수 있다. 웹 수강신청 페지이의 Application programs가 있다. 수강신청 페이지에서 Database에 접근할 때 Database management System을 사용한다. 활용시간 100 중에 Data management system을 사용하는 시간은 1정도.
Presentation Layer, Business Logic Layer, DB Layer 중 가은데 것을 Business Rule이라고 부르기도 하는 듯하다.
- N-Tier Arachitectures
Presentation 앞에 Login만 처리하는 Layer를 하나 더 추가해서 Application이 터지지 않도록 한다.
2.6 Classification of Database Management Systems
DBMS를 구분 분류하는 기준
- Data Model
- 객체지향 DBMS : 객체지향 모델을 지원하는 DBMS
- The number of users : 멀티 유저를 지원하는가 안하는가?
- single-user systems or not
- The number of sites : DB가 얼마나 흩어져있는가?
- centralized / distributed DBMS
- homogeneous / heterogeneous DBMS : 동질형/이질형(여러개의 DB에 대해서 각 DB를 구성하는 모듈이 서로 다른 경우 ORACLE/MSSQL/DB2등으로 다른 경우)
- autonomous하고 기존에 있는 DB에 접속할 수 있게 도와주는 Federated DBMS 연방 DBMS가 있다. Federated DBMS는 교육부가 여러 곳에 흩어져있는 DB를 모은 것이고 이 곳에 접근하면 모든 정보를 얻을 수 있다. distributed DB는 원래 하나를 여러 상황상 여러 나라에 흩어놓은 것이고, Federated DBMS는 원래 다른 것을 하나의 DBMS에서 볼 수 있도록 하는 차이가 있다.
- Cost
- 꽁짜부터 수백만 Dollar짜리. 돈 내는 방법도 여러가지.
- The types of access payh options?
- Purpose
- 범용이나 special purpose냐.
//chapter 1 , 2 review True/False quiz
- 보호(protection)는 하드웨어 또는 소프트웨어 오동작(또는 붕괴)으로부터 시스템을 보호하는 기능(security protection )과 권한이 없는 또는 악의적인 접근을 하려는 보안 위협으로부터 보호하는 기능(system protection)을 포함한다. False
- 어떤 특정 시점에 데이터베이스에 들어 있는 데이터를 데이터베이스 상태(state), 스키마의 내포(intension), 또는 스냅삿(snapshot)이라고 한다. False intension은 아님
- 데이터 모델은 데이터 추상화(data abstraction)를 달성하는 데 필요한 수단을 제공한다. 데이터 타입, 관계성(relationship), 데이터에 대한 제약조건 등의 데이터베이스 구조를 기술하는데 필요한 개념을 포함하지만, 기본 연산 집합은 포함하지 않는다. False S,O,C 모두 포함
- 데이터베이스 설계자(database designer)는 데이터베이스에 저장될 데이터를 선정하고, 데이터를 나타내고 저장하는 구조를 정의하는 역할을 담당한다.
- 3단계-스키마 아키텍처의 목적은 물리적 데이터베이스로부터 사용자 응용들을 분리하는 것이다. 3단계-스키마 아키텍처는 데이터 독립성의 개념을 설명하기 위해 사용될 수 있다.
- 데이터베이스는 서로 연관된 데이터들의 모임이다. 데이터는 기록될 수 있으며 어떤 의미를 내포하고 있는, 알려진 사실(fact)이다.
- 데이터 모델은 데이터를 구조화하는 스키마에 대한 규칙을 제공하며, 스키마는 현실 세계를 표현하는 데이터 인스턴스가 유효한지를 검증하는 규칙을 제공한다.
- DBMS를 접근하는 응용 프로그램들은 데이터 파일의 구조가 응용 프로그램과 분리되어 DBMS 카탈로그에 저장된다. 따라서 데이터 파일의 구조가 변경되어도 응용 프로그램은 거의 변하지 않게 된다. 이러한 성질을 프로그램-데이터 독립성 (program-data independence) 이라 한다.
- 표현(representational) 데이터 모델들은 일반 사용자들이 쉽게 이해할 수 있는 개념을 제공하지만, 컴퓨터 저장 장치에서 데이터가 구성되는 방식과는 완전히 무관하다. False
- 데이터의 중복성(redundancy)은 여러 가지 문제점을 초래한다. 논리적으로는 한 번의 변경이지만 데이터가 중복된 횟수만큼 반복해서 변경해야 하고 메모리 낭비도 초래한다. ```