
[DB] Chapter 1,2,5,6,7,10 정리
Chapter 1
- very large database에서 Data Warehouse 또는
OLAP를 사용해서 business information을 도출할 수 있다. OLAP: Online Analytical Processing- 산업과 제조업에서는 Realtime/active database가 쓰인다.
- database search techniques는 WWW에서 활용되기도 한다.
Terminology
- database : a collection of data
- data : 의미가 있고 저장할 수 있는 알려진 사실
- mini-world : 실제 세계를 보는 관점에 따라서 의미를 다르게 볼 수 있다.
- Ex) 학생을 누구는 ‘가르쳐야하는 대상’으로 보고, 누구는 ‘키워야하는 대상’으로 본다.
- 즉, 같은 대상을 사용하는 목적에 따라서 필요한 데이터가 다르다.
universe of discourse라고도 부른다.
DBMS: Database management System- 사용자가 DB를 생성/사용할 수 있도록 Computerized 된 system
- 사용자와 응용에 따라서
D/C/M/S(Defining/Construcint/manipulating/Sharing)을 DB에 제공하는 general-purpose program이다. Defining: 데이터를 정의- data type, structure, constraints를 정의
- db를 설명하는 데이터도 같이 저장이 되다. (어디에 무슨 데이터가 있는지 설명)
- 위와 같은 정보는
datacase catalogor dictionary에meta-data라는 이름으로 저장된다.
Constructing: 데이터에 값을 넣어주는 행위- DBMS에 의해 관리되는 저장공간에 data를 저장하는 행위
- 적절한 파일에 data를 저장
- 기록들 간의 관계를 저장
Manipulating: 데이터를 지우거나 검색하는 행위- querying for retrieve data /update data / generate report from the data
Sharing: 여러 DB와 유저가 동시에 데이터에 접근하도록 허용
DS: Database system- 전체를 모두 합혀서
DS라고 부른다.
- 전체를 모두 합혀서
Summary
- DB가 아니라 file system을 쓰면 여러 사람이 시스템에 같은 데이터를 저장해야해서 두 가지 문제점이 발생한다.
- 저장공간의 낭비
- 데이터를 update하는데 어려움이 존재
- 해결 방법 : file system에서는 어쩔 수 없는 문제. 따라서 완벽하게 중복을 없애지 않고 최소화하면서 데이터의 일관성을 유지한다.
- 전통적으로,
data structure는 응용프로그램 안에 포함되는 형태였다. 따라서 데이터 구조가 바뀌면 이것에 접근하는 모든 프로그램을 바꿔야했다. file을 가리키는 pointer를 모두 다 바꿔야하는 문제가 있었다. - DBMS를 사용하면,
data structure는 DBMS와 별개로 존재한다. DBMS가 포함하는 것은 structure가 아닌 data이다.program-data-independent한 특성을 갖게 된다.interface of operation과implmentation이 구분되는 것이다.- 유저들은 app implementation에 상관없이 interface만 보고 invoking이 가능해진다.
program-operation-independent한 특성을 갖게 된다.
- 데이터 추상화가
PDI와POI를 가능하게 한다. 사용자에게는 데이터가 표로 저장되어 있다고 생각할 수 있게 해주는 것이다. - 데이터를 한 번에 모아서 보고 싶을 때 데이터를 실제로 모아서 저장하지 않아도 된다.
Concurency control: 여러 유저가 DB에 동시에 접근한다. 이는 file-system과 확실이 구분되는 특성이다.- Ex) 예약 시스템의 경우 중복 예약을 막는 기능이 있어야 한다. 이를
OLTP: Online Transaction processing 이라고 한다. (앞서 이야기한 OLAP와 대비되는 개념)
- Ex) 예약 시스템의 경우 중복 예약을 막는 기능이 있어야 한다. 이를
- transaction properties
- isolation property : 중간에 누가 훼방을 놓을 수 없는 특성
- atomicity property : 가장 작은 단위
- Actors on the Scenes : 매일 매일 DB 접근을 하는 사람들
DBA: Database administrator, DB 전체를 관리하는 사람. 사용을 허락해주고 모니터링하고 필요한 S/W 부품을 추가하고 보안에 대해서 책임을 지는 사람- DB designer : DB에 저장될 data를 identify하고 data를 잘 표현하는 구조를 짜는 사람
- 잠재적인 사용자 집단과 소통하며 DB의 view를 개발하고, 사용자의 requirement를 만족시킨다.
- end users
- Integrity Constaints
- `Referential integrity Constraint : 참조 무결정
- 가장 기본적인 constraint
- 각각의 data item에 대해 특정 data type을 포함하도록 하는 것
- Ex) 사원 정보에 이름이 빠지면 안되니까 이를 constraint로 막는다.
- Uniqueness Constraint or Key
- Ex) 각 수업은 고유한 Coure_number를 가져야 한다. 겹치면 안된다.
- `Referential integrity Constraint : 참조 무결정
- 역사, 발전의 흐름
- 데이터가 어디있는지를 까먹었다.
- 포인터로 관계를 지칭했다. 데이터를 옮기면 포인터를 다 바꿔야 했다.
- 관계형 DB : 메모리 주소를 몰라도 관계를 알면 데이터를 찾을 수 있게 되었다.
- OOP의 개념을 적용한 DBMS를 시도했지만 어려워서 실패했다.
- Web을 DB로 관리하기 위해서
XML(eXtended Markup language) 등장 - OODB의 모든 기능은 relational DB에 포함되었고, 필요하면 쓸 수 있게 되었다.
- 필요한 library를 사서 사용할 수 있게 되었다.
- 새로운 형태의 데이터(posts,tweets,…) 가 등장하면서
SQL(standard Query Language)에 적합하지 않게 되었다. NOSQL: Not Only SQL, 몇몇 데이터는 SQL 몇몇 데이터는 NOSQL
- DBMS는 concurrency control이 제일 어렵다.
- Real time 특성이 굉장히 큰 프로젝트(Ex. 미사일)은 DB에 적합하지 않다.
Chapter 2
- 데이터 추상화 : detail suppression, 중요한 정보는 남기기. 사용자가 원하는 level의 data detail을 볼 수 있도록 함
data model: DB 구조를 설명하기 위해서 사용되는 개념의 집합- high level data model : 유저가 데이터를 얻는 방향에 가깝게 정의
- low level data model : 데이터가 저장되는 방향에 가깝게 정의
- entitiy : mini-world 에서의 object
- attribute : entity의 property
- relationship : entity간의 association
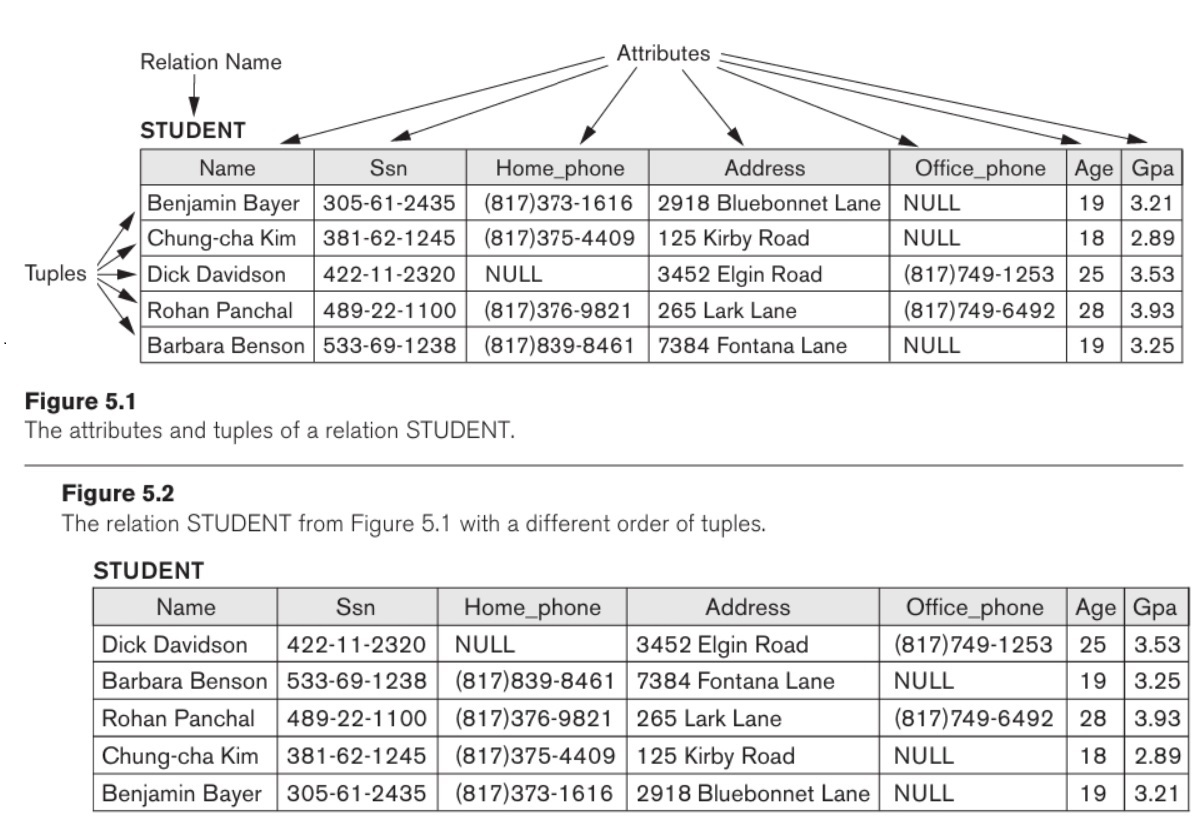
- database state/snapshot : 특정 순간의 저장된 data
- state = snapshot = current set of occurences = instance
- DBMS는 모든 snapshot이 valid하게 만들어야 한다. 구조를 만족하고 제약조건을 만족해야 한다.
- intension : description of the schema constructs and constraints
- extension : database state
Data model
- Data model? : databae 구조를 설명하기 위해서 사용되는 여러가지 개념들의 집합. 일반적으로 basic operation도 포함된다.
- database 구조? : data에 적용되는 data types, relationshop, constraints
- 용도 : 데이터 추상화를 위한 여러가지 수단을 제공
DB 구조를 설명하기 위해서 여러 가지 data model들이 제안되었습니다. 이들은 각각의 concept를 가지고 DB구조를 설명하려고 합니다.
- High Level data model = conceptual data model
- 많은 유저가 데이터를 인식하는 방법과 비슷한 방법의 컨셉을 제공합니다.
- entities, attributes, relationships
- emtity : a real world object or concept. Ex) employee or project
- attribute : entitiy를 설명하는 property. Ex) employee의 name
- relationship : 다수의 entitiy 들 사이의 관계
- Representational data model = implementation data models
- 유저에게도 쉽게 이해가 되고, 데이터가 스토리지에 저장되는 방식과도 너무 동떨어지지 않게 설명합니다. 이 데이터 모델은 데이터 스토리지의 많은 디테일을 숨기면서 implmented될 수 있도록 합니다.
- Low Level data model = physical data models
- 어떻게 데이터가 스토리지에 저장되는지에 대한 컨셉을 묘사합니다.
- record formats, record orderings, access paths
- access path : 특정한 database 기록을 찾기 위한 탐색 구조를 말합니다. indexing이나 hashing을 의미합니다.
Two Tier Client/Server Architectures for DBMSs
centralized DBMS에서는 client는 user interface와 application을 담당합니다. server가 담당하는 기능으로는 query/transaction functionality와 related to SQL processing이 있습니다. SQL이 Relational DBMS에게 표준 언어를 제공하기 때문에 client 와 server 사이에는 논리적인 구분이 가능하게 됩니다. 이 말은 사용자가 여러 DB(ORACLE, DB2 등)를 사용할 때 중간 표준 interface만 알도록 하는 것을 의미합니다. C/C++ 사용자는 ODBC만 알면되고, java 사용자는 JDBC만 알면 됩니다.
Three Tier and N Tier Architecture

low level에서부터 설명합니다.
- internal level은 internal schema를 가지고 있습니다. 이것은 database의 physical storage structure를 묘사합니다. internal schema는 physical data model을 사용하고 data storage와 database의 access paths에 대한 완벽한 디테일을 묘사합니다.
- conceptual level은 conceptual schema를 가지고 있습니다. 이것은 전체 database의 구조를 커뮤니티 유저들을 위해서 묘사합니다. 이는 physical storage structure의 디테일을 숨기고, entity와 data types, relationships, user operations, 그리고 constraints를 묘사합니다. 대게 representational data model은 대게 database system이 implemented될 때, conceptual schema를 묘사하기 위해서 사용됩니다.
Logical data independence: the capacity to change the conceptual schema without having to change external schemas or application programs.
we may change the conceptual schema to expand the database (by adding a
record type or data item), to change constraints, or to reduce the database
(by removing a record type or data item). In the last case, external schemas
that refer only to the remaining data should not be affected. For example,
the external schema of Figure 1.5(a) should not be affected by changing the
GRADE_REPORT file (or record type) shown in Figure 1.2 into the one
shown in Figure 1.6(a). Only the view definition and the mappings need to
be changed in a DBMS that supports logical data independence. After the
conceptual schema undergoes a logical reorganization, application pro-
grams that reference the external schema constructs must work as before.
Changes to constraints can be applied to the conceptual schema without
affecting the external schemas or application programs.
Physical data independence: the capacity to change the internal schema without having to change the conceptual schema.
Hence, the external sche-
mas need not be changed as well. Changes to the internal schema may be
needed because some physical files were reorganized—for example, by cre-
ating additional access structures—to improve the performance of retrieval
or update. If the same data as before remains in the database, we should not have to change the conceptual schema. For example, providing an access
path to improve retrieval speed of SECTION records (Figure 1.2) by semes-
ter and year should not require a query such as list all sections offered in fall 2008 to be changed, although the query would be executed more efficiently by the DBMS by utilizing the new access path.