
[RoadMap] Chap 0. Internet(Application layer)
본 포스팅은 kamranahmedse의 개발자 로드맵을 따라서 진행됩니다.
How does the internet work?
구성요소로 본 인터넷
인터넷에 연결되는 모든 장치는 호스트host 혹은 엔드 시스템end system이라고 부릅니다. host는 통신 링크communication link와 패킷 스위치packet switch의 네트워크로 연결됩니다.
communication link는 광케이블, 구리선 등의 물리 매체로 구성됩니다. 이때 각각의 link는 다양한 전송률transmission rate과 대역폭bandwidth를 이용해서 데이터를 전송합니다. 전송률은 초당 비트 수를 의미하는 bps(bit per second) 단위를 사용합니다. 하나의 host에서 다른 host로 데이터를 보낼 때, host는 데이터를 segment로 나누고 각 segment에 header를 붙입니다. 이렇게 만들어진 것을 패킷packet이라고 부릅니다. packet은 네트워크를 통해서 목적지 host로 보내진 뒤에 다시 원래의 데이터로 조립됩니다.
packet switch는 입력 통신 링크의 하나에서 도착하는 패킷을 받아서 출력 통신 링크의 하나로 그 패킷을 전달합니다. packet switch의 종류로는 라우터router와 링크 계층 스위치link-layer switch가 있습니다. 두 형태의 스위치 모두 최종 목적지 방향으로 패킷을 전달합니다. 전자는 보통 네트워크의 중심부(코어)에서 사용되고, 후자는 access network(네트워크의 끝 단)에 사용됩니다.
host들은 ISP(Internet Service Provider)를 통해서 인터넷에 접속합니다. ISP는 packet switch와 communication link로 구성된 네트워크입니다. 인터넷은 host들을 서로 연결하는 것이므로 host에 접속을 제공하는 ISP들도 서로 연결되어야 합니다.
host, packet switch 그리고 인터넷의 다른 구성요소들은 정보의 송수신을 제어하는 여러 프로토콜protocol을 수행합니다. 특히 TCP(Transmission Control Protocol)와 IP(Internet Protocol)은 인터넷에서 가장 중요한 프로토콜입니다. TCP는 데이터가 전송되는 방식에 대한 규칙이고, IP는 전송되는 데이터의 포멧 규칙을 의미합니다. TCP와 IP를 합쳐 TCP/IP라고 부릅니다. 프로토콜은 둘 이상의 host 간에 교환되는 메시지 포멧과 순서뿐 아니라, 메시지의 송수신과 다른 이벤트에 따른 행동까지 정의합니다.
서비스 측면에서 본 인터넷
인터넷은 app에 서비스를 제공하는 infra 구조로서의 의미를 가집니다. 수 많은 app들은 서로 데이터를 교환하는 많은 host를 포함하고 있기 때문에 분산 앱Distributed Application이라고 부릅니다. 중요한 것은 인터넷 app이 host에서 수행된다는 점입니다. app은 네트워크 core에서 수행되지 않습니다. packet switch들은 host간에 데이터 교환을 쉽게 해주지만 데이터의 시작과 끝안 app에는 관심을 가지지 않습니다. 인터넷에 접속된 host들은 소켓 인터페이스socket interface를 제공합니다. 소켓 인터페이스는 데이터를 송신파느 프로그램이 따라야 하는 규칙의 집합이며, 인터넷은 이 규칙에 따라서 데이터를 목적지 프로그램으로 전달합니다. 예를 들어 우체국을 통해서 우편을 보낼 때 이름,주소를 적고 우표를 붙히는 드으이 과정을 따르는 것이 우편 인터페이스르 따르는 것이라고 할 수 있습니다.
Access Network
접속 네트워크는 host를 그 host로부터 다른 먼 거리에 있는 host까지의 경로 상에 있는 첫 번째 router에 연결하는 네트워크입니다. 접속 네트워크로서 이전에는 DSL(digital subscriber line)을 사용했습니다. 기존에 존재하는 전화 기반 구조를 사용해서 인터넷 신호를 받아오는 방식입니다. 최근에는 케이블 인터넷 접속방식을 많이 사용합니다. 이는 케이블 TV 기반구조를 이용합니다. 케이블 회사가 제공하는 케이블 모뎀 안에는 이더넷 포트가 있는데 이것을 통해서 가정의 PC에 인터넷이 연결됩니다. 가정에서 사용하는 LAN(local area network)는 일반적으로 host를 가장자리 router에 연결하기 위해서 사용합니다. LAN 기술 중 가장 일반적으로 사용되는 것이 이더넷입니다. 이더넷 스의치 혹은 상호연결된 스위치들의 네트워크는 점점 더 큰 인터넷으로 연결됩니다. 인터넷이 글로벌 네트워킹에 대한 것이라면, 이더넷은 근거리 네트워킹에 대한 것입니다. 인터넷이 들어오는 길을 stream이라고 표현할 때, 보통 다운스크림과 업스트림이 구분됩니다. 전자는 가정 host에서 데이터를 받을 때, 후자는 데이터를 보낼 때 사용합니다. 일반적으로 다운스트림 채널이 업스트림 채널보다 빠른 전송속도를 가집니다. 무선 LAN 환경에서 무선 사용자들은 기업 네트워크에 연결된 Access Point로 패킷을 송신/수신하고, 이 Access point는 유선 네트워크에 다시 연결됩니다.
Core Network
송신 host와 수신 host 사이에서 각 패킷은 통신 링크와 패킷 스위치(router or link-layer switch)를 거치게 됩니다. 이 때 패킷은 링크의 최대 전송 속도와 같은 속도로 각각의 통신 링크상에서 전송됩니다. 따라서 송신 종단 시스템 혹은 해킷 스위치가 R bps의 속도로 링크상에서 L bits의 패킷을 송신했다면 그 패킷을 전송하는데 걸리는 시간은 L/R초입니다.
대부분의 패킷 스위치는 저장 후 전달 전송(Store and forward transmission) 방식을 이용합니다. 이는 출력 링크로 패킷의 첫 비트를 전송하기 전에 전체 패킷을 받아야 함을 의미합니다. 송신 host에서 L bits짜리 패킷 3개개를 목적지 host로 보내는 상황을 가정해보겠습니다. 송신 host는 시간 0에 전송하기 시작합니다. L/R초 만에 송신 시스템은 첫 번째 전체 패킷을 전송을 완료합니다. 그리고 라우터는 L/R초에서 패킷을 전송하기 시작하고 목적지 host에는 2L/R초에 첫 번째 패킷을 전송받습니다. 따라서 전체 지연은 2L/R초입니다. 그리고 전체 패킷이 목적지에 도달할 때까지 걸리는 시간은 4L/R초가 됩니다.
회선 교환과 패킷 교환
링크와 스위치의 네트워크를 통해 데이터를 전송시키는 방식에는 회선 교환circuit switching과 패킷 교환packet switching이라는 두 가지 기본 방식이 있습니다. 회선 교환 네트워크에서 host간에 통신을 제공하기 위해 경로상에 필요한 자원(버퍼, 링크 전송률)은 통신이 진행 중인 동안에 확보(예약)됩니다. 그리고 패킷 교환 네트워크에서는 이들 자원을 예약하지 않습니다. 대신 자원은 on-demand 방식으로 요청되고 이 때문에 통신 링크에 접속하기 위해서 기다릴 수 있습니다.
회선circuit은 두 host간에 연결을 설정하기 위해서 경로 상에 있는 스위치들이 해당 연결 상태를 유지해야하는 것을 의미합니다. 연결이 이루어지는 동안 자원을 예약하기 때문에 송신자는 수신자에게 일정한 전송률로 데이터를 보낼 수 있습니다. 두 host를 연결하는 링크가 있습니다. 그리고 이 하나의 링크는 4개의 회선으로 구성된다고 가정하겠습니다. 송신 host가 하나의 라우터를 거쳐서 수신 host로 통신을 할 때 총 2개의 링크를 지나고, 이 때 각각의 링크에 속에 있는 회선 중 하나를 예약합니다. 따라서 이 연결이 진행될 때는 링크 전체 전송 용량의 1/4를 얻을 수 있습니다.
패킷 교환 네트워크에서는 host를 잇는 링크의 자원을 예약하지 않고 packet을 주고 받습니다. 계속해서 데이터 stream을 보내는 것이 아니라 그 때 그 때 data를 packet으로 자르고 이를 전송하기 위한 자원을 잠깐 잠깐 사용합니다. 인터넷은 최대한 빠르게 패킷을 전달하려고 하지만 일정 시간 내에 전달되는 것이 보장되지는 않습니다.
계층 구조
네트워크 설계자는 프로토콜을 계층적으로 조직했습니다. 한 계층이 상위 계층에 제공하는 서비스에 관심을 갖고, 이것을 계층의 서비스 모델이라고 합니다. 예를 들어서 공항에서 티켓팅을 할 때 수하물 검사의 과정은 자세히 알지 않고 수하물 검사 서비스를 진행하는 것에만 집중합니다. 수하물 검사를 진행하는 부서에서는 수하물의 운반의 과정은 알지 못하고 수하물 운반 서비스를 사용해서 수하물 검사 서비스를 제공합니다. 네트워크를 구성하는 하드웨어와 소프트웨어를 계층적으로 구분한 것이 프로토콜 스택protocol stack입니다.
5개 계층의 인터넷 프로토콜 스택은 다음과 같습니다.
- 애플리케이션
- 네트워크 App과 애플리케이션 계층의 protocol이 존재합니다.
- HTTP, SMTP, FTP와 같은 프로토콜을 포함합니다.
- 정보 패킷 : Message
- 트랜스포트
- 클라이언트와 서버 간에 애플리케이션 계층의 미시지를 전송하는 서비스를 제공합니다.
- TCP, UDP를 포함합니다.
- TCP는 긴 메시지를 짧은 메시지로 나누고 혼잡제어 기능을 제공합니다. 네트워크가 혼잡할 때는 출발지의 전송속도를 줄입니다.
- UDP는 비연결형 서비스를 제공합니다. 신뢰성, 흐름제어, 혼잡제어의 기능을 제공하지 않습니다.
- 정보 패킷 : Segment
- 네트워크
- 정보 패킷 : datagram
- 트랜스포트 계층은 Segment와 목적지 주소를 네트워크 계층으로 전송합니다.
- 네트워크 계층은 Segment와 목적지 주소를 받아서 Segment를 datagram로 나눈 뒤 routing하는 역할을 맡습니다.
- IP를 포함합니다.
- 링크
- 링크 계층은 datagram을 경로상의 다음 노드에 전달합니다.
- 정보 패킷 : frame
- 물리
- frame 내부의 각 bit를 한 노드에서 다른 노드로 전송시킵니다.
OSI 7개 계층의 프로토콜 스택은 다음과 같습니다.
- 애플리케이션
- 프레젠테이션
- 애플리케이션들이 교환되는 데이터의 의미를 해석하도록 하는 서비스를 제공합니다.
- 데이터 기술 뿐만 아니라
데이터 압축과데이터 암호화를 포함합니다.
- 세션
- 데이터 교환의 경계와
동기화를 제공합니다.
- 데이터 교환의 경계와
- 트랜스포트
- 네트워크
- 링크
- 물리
What is HTTP?
HTTP는 애플리케이션 계층에서 사용되는 프로토콜이기 때문에 애플리케이션 계층에 대한 간략한 이해를 포함해서 진행하겠습니다.
네트워크 애플리케이션의 원리
어떤 앱을 만들 때 라우터나 링크 계층 스위치 같이 네트워크 코어 장비에서 실행되는 소프트웨어를 작성할 필요는 없습니다. 이러한 내용은 애플리케이션 계층에서 기능하지 않는 대신 네트워크 계층 및 그 하위 계층에서 기능합니다. 앱 개발자는 네트워크 구조는 고정되어 있음을 가정합니다. 대신에 애플리케이션 구조는 앱 개발자에 의해서 설계되고 다양한 host에서 어떻게 조직되어야하는 지를 지시합니다.
클라이언트-서버 구조에서 항상 켜져 있는 host는 서버이고, 이 서비스는 클라이언트라는 많은 host의 요청을 받습니다. 클라이언트-서버 구조에서 이들은 서로 직접적으로 통신하지 않습니다. 예를 들어서 웹 앱에서는 두 개의 브라우저가 직접적으로 통신하지 않습니다. 그리고 클라-서버 구조에서는 서버가 고정 IP 주소라는 잘 알려지 주소를 사용합니다. 서버는 항상 동작하기 때문에 클라이언트는 서버 주소로 패킷을 보내서 항ㅅ아 서버에 연결할 수 있습니다. 하나의 서버에 수 많은 클라가 접속된다면 서버가 모든 클라에 응답하지 못할 수 있습니다. 그래서 구글같은 거대하 기업은 데이터 센터를 두어서 수십만개의 서버를 갖추고 있습니다.
P2P 구조에서는 항상 켜져 있는 기반 구조 서버에 최소로 의존합니다.(혹은 전혀 의존하지 않습니다.) 대신에 앱은 Peer라는 간헐적으로 연결된 호스트 쌍이 직접 통신합니다. 여러 링크 경로를 지나서 데이터가 서버에 닿았다가 다시 목적지 host로 가는 것이 아니라, 바로 목적지 host로 가는 것을 말합니다. P2P 구조의 특징은 자가 확장성self-scalability입니다. 예를 들어서 P2P 파일 공유 앱에서 비록 각 피어들이 파일을 요구함으로써 작업 부하를 만들어내지만, 각 피어들은 또한 파일을 다른 피어들에게 분배함으로써 그 시스템에 서비스 능력을 추가합니다. P2P는 고도의 분산 구조적 특성으로 보안과 성능 이슈가 존재합니다.
Session
세션Session의 사전적인 정의는 다음과 같습니다.
- 네트워크 환경에서 사용자 간 또는 컴퓨터 간의 대화를 위한 논리적인 연결.
- 프로세스들 사이에서 통신을 하기 위해서 메시지 교환을 통해 서로를 인식한 후 이후부터 통신을 마칠 때까지의 기간.
좀 더 쉽게 설명하면 아래와 같습니다.
- 일정 시간동안 같은 사용자(정확하게는 브라우저)로부터 들어오는 일련의 요구를 하나의 상태로 보고 그 상태를 일정하게 유지시키는 기술
- 일정 시간이란 방문자가 웹 브라우저를 통해 웹 서버에 접속한 시점으로부터 웹 브라우저를 종료함으로써 연결을 끝내는 시점
Cookie
쿠키는 방문자의 정보를 방문자 컴퓨터의 메모리에 저장하는 것을 말합니다. 예를 들면 ID나 비밀번호를 저장하거나 방문한 사이트를 저장할 때 사용합니다.
세션은 방문자의 요청에 따른 정보를 방문자 메모리에 저장하는 것이 아니라, 웹 서버가 세션 아이디 파일을 만들어 서비스가 돌아가고 있는 서버에 저장하는 것을 말합니다.
클라이언트와 서버
두 프로세스 간의 통신 세션에서 통신을 초기화하고(다른 프로세스와 세션을 시작하려고 접속을 초기화)하는 프로세스를 클라이언트라고 하고, 세션을 시작하기 위해 접속ㅇ르 기다리는 프로세스를 서버라고 합니다.
Socket
하나의 프로세스로부터 다른 프로세스로 보내는 메시지는 네트워크를 통해 움직입니다. 프로세스는 소켓Socket을 통해서 네트워크로 메시지를 보내고 받습니다. 소켓은 집의 문과 같은 역할을 합니다. 프로세스가 메시지를 다른 호스트의 프로세스로 보내고 싶을 떄, 메시지를 보내는 socket으로 보냅니다.
소켓은 host의 애플리케이션 계층과 트랜스포트 계층 간의 인터페이스 입니다. 또한 소켓은 네트워크 애플리케이션이 인터넷에 만든 프로그래밍 인터페이스이므로, 애플리케이션과 네트워크 사이의 API(Application Programming Interface)라고도 합니다.
IP, port number
데이터를 보낼 때 어떤 호스트의 어떠 프로세스로 보낼지를 결정해야합니다. IP는 호스트를 식별할 때 사용되고, port number는 호스트의 프로세스를 식별할 때 사용됩니다.
HTTP Session
세션은 서버가 해당 서버로 접속한 클라이언트를 식별하는 방법입니다. 서버는 접근한 클라이언트에게 response-header field인 set-cookie값으로 클라이언트 식별자인 session-id를 발행합니다. 서버가 Session id를 만든다고 보면 됩니다. 서버로부터 발행된 session-id는 해당 서버와 클라이언트 메모리에 저장됩니다. 이 때 클라이언트 메모리에 사용되는 cookie는 Session이 종료될 때 같이 소멸되는 Memory Cookie가 사용됩니다.
HTTP Session의 동작 순서는 아래와 같습니다.
- 클라이언트가 서버로 접속(http요청)을 시도합니다.
- 서버는 접근한 클라이언트의
request-header field인cookie를 확인해 클라이언트가 해당 session-id를 보내왔는지 확인합니다. - 만약 클라이언트로부터 전송된 session-id가 없으면, 서버는 session-id를 생성해서 클라이언트에게
response-header field인set-cookie값으로 session-id를 보내줍니다.
HTTP 개요
HTTP는 웹의 애플리케이션 계층 프로토콜입니다. HTTP는 클라이언트 프로그램과 서버 프로그램으로 구현됩니다. 서로 다른 종단 시스템에서 수행되는 두 프로그램은 서로 HTTP 메시지를 교환하여 통신합니다. HTTP는 통신되는 메시지가 어떤 구조를 가지고 어떻게 통신되는지를 정의합니다.
웹 페이지는 여러 객체들로 구성됩니다. 객체는 단일 URL로 지정할 수 있는 하나의 파일입니다. 예를 들면 HTML, JPEG, GIF 이미지 등입니다. 대부분의 웹페이지는 기본 HTML 파일과 여러 참조 객체로 구성됩니다. 기본 HTML 파일은 페이지 내부의 다른 객체를 그 객체의 URL로 참조합니다.
각 URL은 두 가지 요소로 구성됩니다. 객체를 갖고 있는 서버의 host name과 객체의 경로이름입니다.
https://github.com/niklasjang/niklasjang.github.io/blob/master/assets/images/ml/cnn-0.jpg
{kind=link}
다음과 같은 URL이 있을 때 https://github.com은 호스트 네임이고 나머지는 경로 이름입니다. 웹 브라우저는 HTTP의 클라이언트 측을 구현합니다. 따라서 웹의 관점에서 브라우저와 클라이언트라는 용어는 혼용되서 사용됩니다. 웹 서버는 HTTP의 서버측을 구현합니다. 웹 서버는 URL로 각각 지정할 수 있는 웹 객체를 가지고 있습니다. 인기 있는 웹 서버로는 아파치가 있습니다.
Browers and how they work?
HTTP 요청
HTTP는 웹 클라이언트가 웹 서버에게 웹 페이지를 어떻게 요청하는지와 서버가 클라이언트로 어떻게 웹 페이지를 전송하는지를 정의합니다. 사용자가 웹 페이지를 요청할 때, 브라우저는 페이지 내부의 객체에 대한 HTTP 요청 메시지를 서버에 보냅니다. 서버는 요청을 수신하고 객체를 포함하는 HTTP 응답 메시지를 보냅니다.
HTTP는 TCP를 전송 프로토콜로 사용합니다. HTTP 클라이언트는 먼저 서버에 TCP 연결을 시작합니다. 일단 연결이 이루어지면, 브라우저와 서버 프로세스는 그들의 소켓 인터페이스를 통해 TCP로 접속합니다. 클라이언트 측에서 보면 소켓은 클라이언트 프로세스와 TCP 연결 사이의 출입구이고, 서버 측에서 보면 소켓은 서버 프로세스와 TCP 연결 사이의 출입구입니다.
클라이언트는 HTTP 요청 메시지를 소켓으로 보내고, 응답 메시지를 받을 때도 소켓으로 받습니다. 마찬가지로 HTTP 서버도 같습니다. HTTP는 전송 프로토콜로 TCP를 사용하고, TCP는 신뢰적인 통신을 보장합니다. 데이터가 목적지로 도착하는 것을 보장하는 서비스를 제공하는 것입니다. 따라서 클라이언트 프로세스가 발생시킨 모든 HTTP 요청 메시지가 궁극적으로 서버에 잘 도착한다는 것을 의미합니다.
서버가 클라이언트에게 요청 정보는 보낼 때, 서버는 클라이언트에 관한 어떤 정보도 저장하지 않습니다. 만약 같은 정보를 여러번 요청해도 아까 그 파일을 보냈다는 신호를 보내지 않도 매번 새로 보내줍니다.
비지속 연결과 지속 연결
클라이언트와 서버가 통신할 때는 수 많은 데이터를 요청하고 응답합니다. 이때 각각의 요청이 분리된 TCP 연결을 통하면 비지속 연결non-persistent connection이라고 하고, 모두 같은 TCP 연결을 통해서 수행되면 지속 연결이라고 합니다. HTTP는 default 값으로 지속연결을 사용합니다.
아래는 비지속 연결의 과정을 보여줍니다.
- 클라이언트와 서버에는 각각 TCP 연결을 위한 소켓이 존재합니다.
- HTTP 클라이언트는 HTTP 기본 포트인 80을 통해 HTTP 서버로 TCP 연결을 시도합니다.
- HTTP 서버는 HTTP 클라이언트의 TCP 연결에 응답합니다.
- TCP 연결이 완료됩니다.
- HTTP 클라이언트는 연결된 TCP 통신을 통해 요청 메시지를 전송합니다.
- HTTP 서버는 연결된 TCP 통신을 통해 요청 메시지를 받습니다.
- HTTP 서버는 저장장치로부터 요청 받은 객체를 추출하고 응답 메시지에 캡슐화합니다.
- HTTP 서버는 응답 메시지를 소켓을 통해 HTTP 클라이언트에게 전송합니다.
- HTTP 서버는 TCP에게 TCP 연결을 끊으라고 합니다.
- HTTP 클라이언트가 응답 메시지를 받으면 TCP 연결이 중단됩니다. 캡슐화된 객체를 추출하고 객체에 대한 참조를 사용자에게 보여줍니다.
위 과정을 객체를 요청받을 때마다 반복해서 진행합니다. 기본적으로 브라우저는 default로서 5~10개의 TCP 연결을 통시에 설정하고 각 연결은 하나의 요청/응답을 처리합니다. 설정을 바꾸면 1개의 TCP 연결만을 설정하고 10개의 요청을 지속적으로 처리할 수도 있습니다.
HTTP 요청 메시지 포멧
GET /somedir/page.html HTTP/1.1
Host : www.someschool.edu
Connectoin : close
User-agent : Mozilla/5.0
Accept-language : fr
위는 기본적인 HTTP 요청 메시지의 포멧을 보여줍니다. 첫 째, ASCII 텍스트로 쓰여있어서 사람이 읽을 수 있습니다. 둘 째, 메시지의 각 줄은 Carriage return & line feed로 구별됩니다. 셋 째, 첫 줄은 request line이라고 부르고 나머지는 header line이라고 부릅니다.
요청 라인은 method, URL, HTTP 버전으로 구성됩니다. method에는 GET, POST, HEAD, PUT 등이 올 수 있습니다. HTTP 메시지의 대부분은 GET을 사용합니다. GET 방식은 브라우저가 URL 필드로 식별되는 객체를 요청할 때 사용합니다.
헤더라인은 객체가 존재하는 호스트를 명시하고 있습니다. 이미 서버와 TCP connection이 연결된 뒤에 주고 받는 HTTP 메시지 이지만 서버의 Host name이 여전히 명시되어 있습니다. 이 부분은 웹 프록시 캐시에서 필요로 합니다.
conncection은 서버에게 지속 연결 사용을 원하지 않는 것을 며이합니다.(브라우저는 서버가 요청 객체를 보낸 후에 TCP 연결을 닫기를 원합니다.)
User-agent는 서버에게 요청을 보내는 브라우저의 타입을 명시합니다.
Accept-language는 사용자가 객체의 프랑스어 버전을 원하고 있음을 나타냅니다. 만약 특정 언어버전이 없다면 기본 버전을 보냅니다.
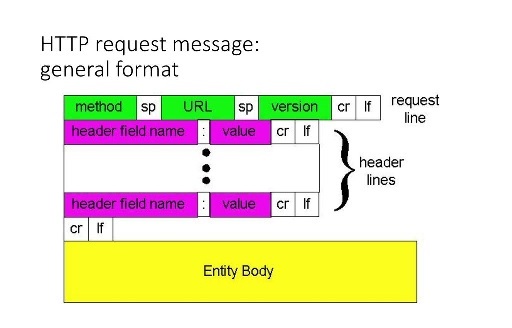
GET 방식에서는 객체 몸체가 비어있고, POST 방식에서는 사용됩니다. 사용자가 form에 내용을 채워넣을 때(검색을 할 때) POST 방식을 사용합니다.
HTTP 응답 메시지 포멧
HTTP/1.1 200 OK
Connection : close
Data : Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-type : text/html
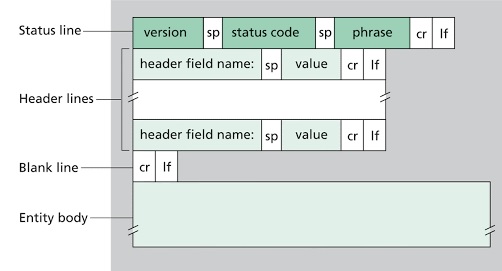
- Connection : close : 클라이언트에게 메시지를 보낸 후 TCP 연결을 닫는 지속 연결을 의미합니다.
- Date : HTTP응답이 서버에 의해서 생성되고 보낸 날짜와 시간입니다. 이 시간이 객체가 생성되거나 마지막으로 수정된 시간이 아닙니다. 서버가 파일 시스템으로부터 객체를 추출하고 응답 메시지에 그 객체를 삽입하여 응답 메시지를 보낸 시간을 의미합니다.
- Server : 메시지가 아파치 웹 서버에 의해서 만들어졌음을 의미합니다.
상태 코드와 문장에 대한 추가 설명입니다.
- 200 OK : 요청이 성공되었고, 정보가 응답으로 보내졌습니다.
- 301 Moved Permanently : 요청 객체가 영원히 이동되었습니다. 새로운 URL은 응답 메시지의 Location: 헤더에 나와있습니다. 클라이언트 소프트웨어는 자동으로 이 새로운 URL을 추출합니다.
- 400 Bad Request : 서버가 요청을 이해할 수 없다는 일반 오류 코드입니다.
- 404 Non Found : 요청 문서가 서버에 존재하지 않습니다.
- 505 HTTP Version Not Supported : 요청 HTTP 프로토콜 버전을 서버가 지원하지 않습니다.
쿠키
HTTP 서버는 연결 상태를 유지하지 않습니다. 서버가 사용자 저복을 제한하거나 사용자에 따라 콘텐츠를 제공하기 원하므로 웹 사이트가 사용자를 확인하는 것이 바람직할 때가 있습니다. 이러한 목적으로 사용하는 쿠키Cookie는 다음과 같은 네 가지 요소로 구성됩니다.
- HTTP 응답 메시지 쿠키 헤더 라인
- HTTP 요청 메시지 코키 헤더 라인
- 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속시키는 쿠키 파일
- 웹 사이트의 백엔드 데이터 베이스
쿠키가 사용되는 방식은 다음과 같습니다.
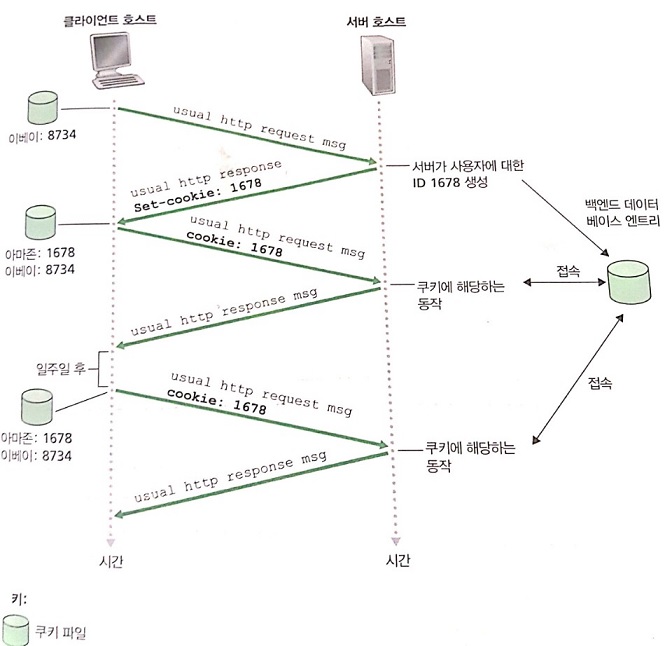
- 사용자는 이전에 이베이 사이트를 접속한 적이 있습니다.
- 사용자는 아마존 사이트에 처음으로 접속을 합니다.
- 아마존 웹 서버는 요청이 드렁왔을 때 유일한 식별변호를 만들고, 이 식별번호로 인덱스 되는 백엔드 데이터베이스 안에 엔트리를 만듭니다.
- 아마존 웹 서버는 사용자의 요청에 응답합니다. 이 때 HTTP 응답에 식별번호를 담고 있는 Set-Cookie: 헤더가 포함되어 있습니다.
- 사용자는 브라우저가 HTTP 응답 메시지를 받았을 때 Set-Cookie 헤더를 보고 쿠키 파일에 그 라인을 덧붙입니다. 이 라인은 서버의 호스트 네임과 Set-Cookie: 헤더와 식별 번호를 포함합니다.
- 사용자는 이전에 방문했던 이베이에 대한 엔트리를 쿠키 파일에 갖고 있음에 유의합니다.
- 사용자가 계속해서 아마존 사이트를 살펴봄에 따라, 웹 페이지를 요청할 때 사용자의 브라우저는 쿠키 파일은 참조하고 이 사이트에 대한 자신의 식별 번호를 발췌하고 HTTP 요청에 식별 번호를 포함하는 쿠키 헤더 파일을 넣습니다. Cookie : 1678
이러한 방법으로 아마존 서버는 사용자의 아마존 사이트에서의 활동을 추적할 수 있습니다. 비록 아마존 웹 사이트는 사용자의 이름을 알 필요는 없지만 1678 사용자아 어떤 페이지를 어떤 순서로 몇 시에 방문했는지는 정확하게 알 수 있습니다. 사용자가 로그인 정보 없이 방문한 기록은 웹 서버의 쿠키 파일에 저장되고, 사용자가 사이트에 등록을 하면 이 정보는 데이터베이스에 저장될 수 있습니다. 이 때 사용자의 식별번호와 사용자의 이름이 매칭됩니다. 이를 통해서 결제 기록을 매번 입력하지 않을 수 있는 것입니다. 정리하자면 쿠키는 사용자의 식별에 사용합니다.
웹 캐싱, 프록시 서버
웹 캐시Web cache 또는 프록시 서버Proxy Server는 웹 서버를 대신해서 HTTP 요구를 충족시키는 네트워크 서버입니다. 웹 캐시는 자체적인 저장 디스크를 가지고 있어 최근 호출된 객체의 사본을 저장 및 보존합니다.
- 브라우저는 웹 캐시와 TCP 연결을 설정하고 웹 캐시에 있는 객체에 대한 HTTP 요청을 보냅니다.
- 웹 캐시는 객체의 사존이 자기에게 저장되어 있는지 확인합니다. 만일 저장되어 있다면 웹 캐시는 클라이언트 브라우저로 HTTP 응답 메시지와 함께 객체를 전송합니다.
- 만일 웹 캐시가 객체를 가지고 있지 않다면, 웹 캐시는 원출처의 서버에 TCP 연결을 설정합니다. 그리고 나서 웹 캐시는 객체에 대한 HTTP 요청을 TCP를 통해 서버로 보냅니다. 서버는 이 요청을 받은 후에 웹 캐시로 HTTP 응답 메시지와 함께 객체를 보냅니다.
- 웹 캐시의 객체를 수신할 때, 객체를 지역 저장장치에 복사하고 클라이언트 브라우저에 HTTP 응답 메시지와 함께 객체의 사본을 보냅니다.
이 때 웹 캐시는 연결 요청을 보내는 클라이언트와 받는 서버의 역할을 모두 수행함에 유의해야 합니다. 웹 캐시는 사용자의 요구에 응답시간을 줄이고, 본 서버로의 트래픽을 줄이는 역할을 합니다. 웹 캐시의 적중률이 40%이고 웹 캐시의 요청 응답 시간은 0.1ms로 즉시 수행된다고 가정해보겠습니다. 그러면 전체 트레픽 강도가 1일 때 0.4는 0.01초 만에 수행되고, 0.6은 일반적인 인터넷 지연(접속 회선 부분의 라우터가 기점 서버들로부터 요청에 대한 응답을 받을 때 걸리는 시간) 2초에 수행됩니다. 따라서 웹 캐시가 있을 때 트레픽강도는 0.4 * 0.01 + 0.6 * 2.01(웹 캐시 탐색 후 인터넷 지연)이 됩니다.
조건부 GET
웹 캐싱이 위와 같은 장점이 있지만, 웹 캐시에 저장된 값이 항상 새로운 값으로 갱신되지 않을 수 있습니다. 조건부 GET은 클라이언트가 브라우저로 전달되는 모든 객체들이 최신의 것임을 확인하면서 캐싱을 하도록 해주는 HTTP의 방식입니다. HTTP 요청 메시지가 GET 방식을 사용하고 If-Midified-Since: 헤더를 포함한다면 조건부 GET 방식의 메시지 입니다.
//브라우저의 요청을 대신에서 웹 캐시가 보내는 요청 매시지
GET /fruit/kiwi.git HTTP/1.1
Host: www.niklasjang.io
//웹 서버의 웹 캐시로의 응답 메시지
HTTP/1.1 200 OK
Data: Sat, 8 Oct 2011 15:35:32
Server: Apache/1.3.0 (Unix)
Last-Mofified: Wed, 7 Sep 2011:09:23:24
Content-Type: image/gif
DATADATADATADATADATADATADATADATADATA
DATADATADATADATADATADATADATADATADATA
웹 캐시는 요청하는 브라우저에 객체를 보내 주고 자신에게도 객체를 저장합니다. 중요한 것은 캐시가 객체와 더불어 마지막으로 수정된 날짜를 함께 저장한다는 것입니다. 일주일 뒤에 다른 브라우저가 같은 객체를 캐시에게 요청하면 객체는 여전히 저장되어 있습니다. 이 객체는 지난주에 웹 서버에서 수정되었으므로 브라우저는 조건부 GET으로 갱신 조사를 수행합니다. 갱신조사는 If-modified-since: 헤더 라인의 값이 일주일 전에 서버가 보낸 값과 정확히 일치하는지를 확인합니다. 만약 변경되지 않았다면 웹 서버는 클라이언트에게 빈 객체 몸체를 포함하는 응답 메시지를 보냅니다.
//웹 서버의 웹 캐시로의 응답 메시지
HTTP/1.1 304 Not Midified
Data: Sat, 8 Oct 2011 15:35:32
Server: Apache/1.3.0 (Unix)
Last-Mofified: Wed, 7 Sep 2011:09:23:24
Content-Type: image/gif
(EMPTY)
What is Domain Name?
호스트 네임은 컴퓨터의 이름입니다. 도메인 네임은 컴퓨터 그룹의 이름입니다. tom.someaddr.com이 있을 때 tom 은 호스트 네임이 되며, sunjin2.net 은 도메인 네임이 됩니다.
DNS and how it works?
DNS
사람처럼 인터넷 호스트도 여러 식별자를 가지고 있습니다. 그 중 하나가 호스트 네임입니다. www.google.com가 구글 호스트의 호스트 네임입니다. 호스트 네임은 기억하기는 쉽지만 그 호스트의 위치 정보를 제공하지 않습니다. 또 호스트 네임은 가변 길이의 alphanumeric한 문자로 구성되기 때문에 router가 처리하는데 어려움이 있습니다. 그래서 네트워크 내부적으로는 host name을 IP address로 변환해서 사용합니다. IP 주소는 4바이트로 구성되고 계층 구조를 가집니다. 127.7.106.83과 같은 형태이고 0~255의 십진수로 표현하는 각 바이트는 점으로 구분됩니다. 각 바이트는 2^0 ~ 2^8-1까지의 숫자를 가질 수 있는 것입니다. IP 주소는 계층 구조이기 때문에 왼쪽에서 오른쪽으로 조사함으로써 그 호스트가 인터넷의 어디에 위치하는지 자세한 정보를 얻을 수 있습니다.
호스트 네임을 IP 주소로 변환해주는 서비스가 DNS(domain name system)입니다. DNS는 (1) DNS 서버들의 계층구조로 구현된 분산 데이터 베이스이고 (2) 호스트가 분산 데이터베이스로 질의하도록 허락하는 애플리케이션 계층의 프로토콜입니다. DNS는 다른 애플리케이션 프로토콜들이 사용자가 제공하는 호스트네임을 IP 주소로 변환하기 위해 주로 이용합니다.
- 사용자 컴퓨터는 DNS 애플리케이션의 클라이언트 측을 수행합니다.
- 브라우저는 URL로 호스트네임 www.google.com을 추출하고 그 호스트 네임을 DNS 애플리케이션의 클라이언트 측에 넘깁니다.
- DNS 클라이언트는 DNS 서버로 호스트 네임을 포함하는 질의를 보냅니다.
- DSN 클라이언트는 결국 호스트 네임에 대한 IP 주소를 응답받습니다.
- 브라우저가 DNS로부터 IP 주소를 받으면, 브라우저는 그 IP 주소와 그 주소의 80번 포트에 위치하는 HTTP 서버 프로세스로 TCP 연결을 초기화 합니다.
- 원하는 IP 주소는 가까운 DNS 서버에 캐시되어 있습니다.
그리고 아래와 같은 추가적인 서비스를 제공합니다.
- host aliasing : 복잡한 호스트 네임을 가진 호스트는 아라 이상의 별명을 가질 수 있습니다.
- mail server aliasing : 전자 메일 주소에 대한 aliasing을 제공합니다. 메일 주소가 길고 복잡한 경우 사용합니다.
- 부하 분산load distribution : 중복 웹 서버 같은 여러 중복 서버 사이에 부하를 분산하기 위해서도 사용됩니다. google.com 같은 웹 서버는 여러 개의 서버가 중복되어 있습니다. 그리고 각 서버가 다른 종단 시스템에서 수행되고 서로 다른 IP 주소를 가집니다. DNS 데이터베이스는 이 IP 주소 집합을 가지고 있어서 하나의 정식 호스트 네임과 연관시킬 수 있습니다.
DNS 서버의 사용자 관점에서는 다음과 같은 방식으로 진행됩니다. 사용자의 호스트에서 실행되는 어떤 앱(웹 브라우저나 메일 리더)이 호스트 네임을 IP 주소로 변환시키려 한다고 가정하겠습니다. 그 앱은 변환될 호스트 네임을 명시해서 DNS 측의 클라이언트를 호출합니다. 많은 unix 기반의 컴퓨터에서는 gethostbyname()가 변환 실행하기 위한 애플리케이션을 호출하는 함수입니다. 그리고 사용자 호스트의 DNS는 네트워크에 질의 메시지를 보냅니다. 수 msec에서 수 sec의 지연 후에 사용자 호스트의 DNS는 요청한 DNS 응답 메시지를 받습니다.
DNS 서버의 구조는 분산 계층 데이터베이스를 기반으로 합니다.
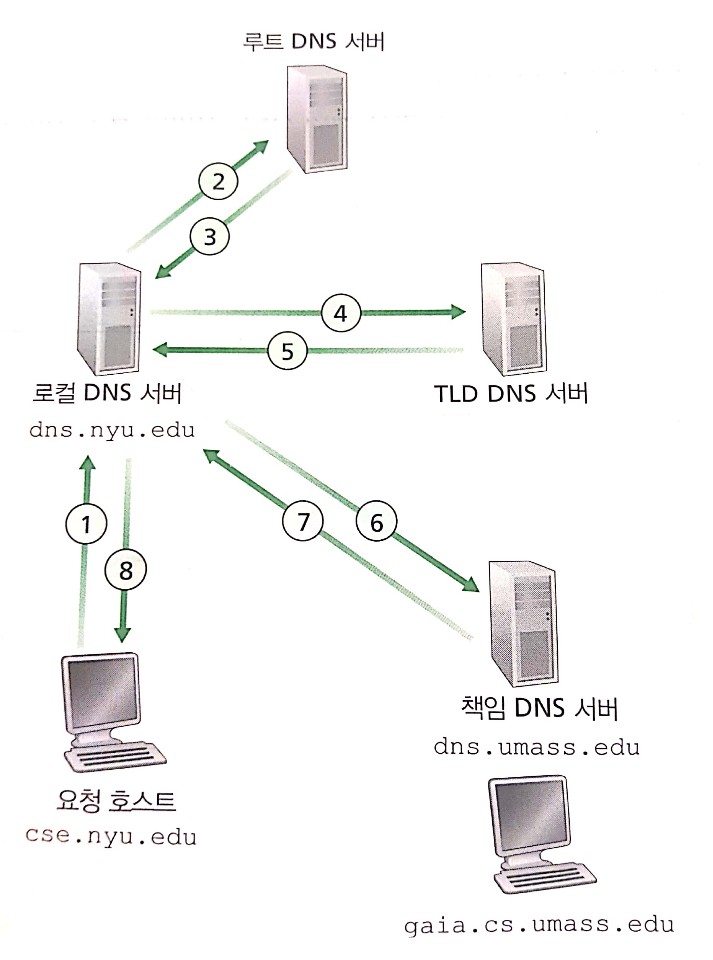
- 루트 DNS 서버 : Root DNS 서버
- 최상위 레벨 도메인 서버 : com DNS 서버 / org DNS 서버 / edu DNS 서버
- 책임 DNS 서버 : facebook.com DNS 서버 / pbs.org DNS 서버 / umass.edu DNS 서버 …
책임 DNS 서버는 다음과 같은 의미입니다. 인터넷에서 접근하기 쉬운 호스트(웹 서버, 메일 서버 등)을 가진 모든 기관은 호스트 네임을 IP 주소로 맵핑하는 공개적인 DNS 레코드를 제공해야합니다. 기관읜 책임 DNS 서버는 이 DNS 레코드를 갖도록 설정할 수 있고, 다른 서비스 제공자의 책임 DNS 서버에 이 레코드를 저장하도록 비용을 지불할 수도 있습니다.
로컬 DNS 서버의 개념도 중요합니다. 로컬 DNS 서버는 서버들의 계층구조에 엄격하게 속하지는 않지만, DNS 구조의 중심에 있습니다. 요청 호스트가 요청을 날리면 바로 루트 DNS 서버로 요청이 보내지기 전에 로컬 DNS 서버가 proxy의 역할을 합니다. 중간에서 먼저 요청을 받고 root로 보내주는 역할을 합니다. 요청을 받은 루트 DNS 서버는 요청받은 호스트 네임을 관장하는 TLD DNS 서버의 주소를 로컬 DNS 서버에 보내고, 로컬 DNS 서버는 다시 TLD DNS 서버에 보냅니다. 같은 방식으로 책임 DNS 서버에 마지막으로 요청을 보내서 응답을 받고 최초의 요청 호스트에 IP 주소를 전달합니다.
DNS Cache
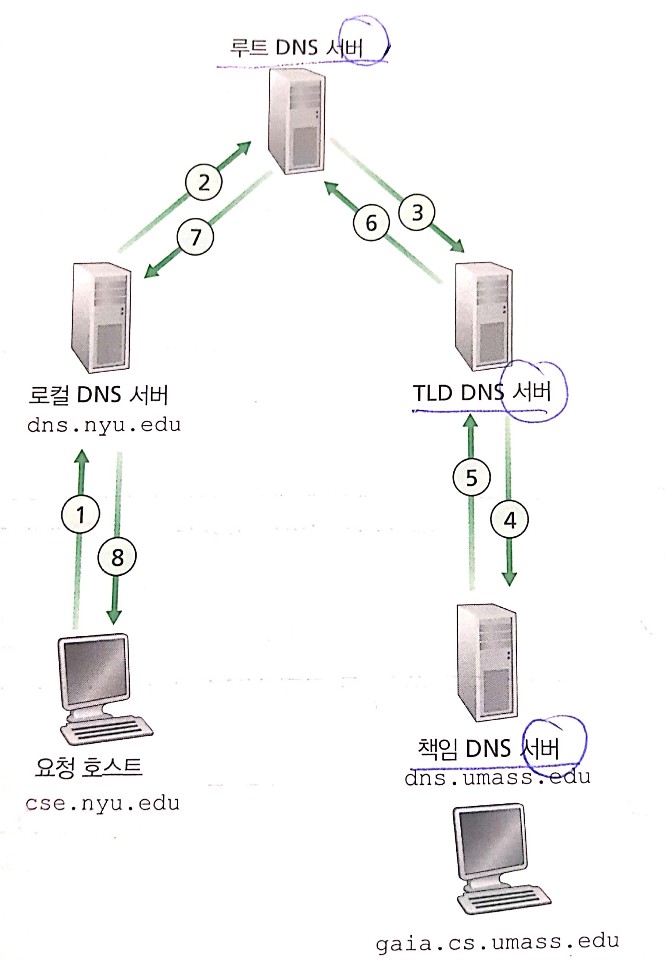
DNS 서버는 DNS 응답을 받았을 때 응답 정보를 로컬 메모리에 저장할 수 있습니다. 따라서 DNS 서버는 호스트 네임에 대한 책임이 없는 부분까지 기억해서 IP 주소를 제공할 수 있습니다. 일반적으로 DNS 서버의 cache 저장기한은 2일입니다. 그리고 로컬 DNS 서버는 TLD 서버의 IP 주소를 저장할 수 있습니다. 그러므로 로컬 DNS 서버가 질의 사슬에서 루트 DNS 서버를 우회하도록 합니다.
저장되는 포멧은 (Name, Value, Type, TTL)입니다.
- Type == A : Name은 호스트 네임, Value는 호스트 네임에 대한 IP 주소
- Ex) (relay1.bar.foo.com, 145.37.93.126, A)
- Type == NS : Name은 도메인(foo.com), Value는 도메인 내부의 호스트에 대한 IP 주소를 얻을 수 있는 방법을 아는 책임 DNS 서버의 호스트 네임
- Ex) (foo.com, dns.foo.com, NS)
- Type == CNAME : Name은 정식호스트 네임, Value는 별칭 호스트 네임
- Ex) (foo.com, relay1.bar.foo.com, CNAME)
- Type == MX : Name은 메일 서버의 정식 이름, Value는 별칭 호스트 네임
- Ex) (foo.com, mai.bar.foo.com, MX)
한 DNS 서버가 특정 호스트 네임에 댛나 책임 서버라면 Type A 레코드를 포함합니다. 만약 아니라면 그 서버는 Type NS를 포함합니다.
What is hosting?
호스팅이랑 서버의 전체 혹은 일부를 이용할 수 있도록 임대해주는 서비스를 말합니다. 서버를 관리하기 위해서는 24시간 내내 안정적으로 전기를 공급해야하고, 빠르고 안정적인 인터넷 회선을 사용해야 하며, 철저한 보안 시스템을 갖추고 있어야 합니다. 따라서 개인이 서버를 관리하기 보다는 전문 업체의 호스팅 서비스를 사용하는 것이 일반적입니다.
웹 호스팅은 여러 고객이 하나의 서버를 함께 사용하는 형태입니다. 하나의 서버를 나누어 쓰기 때문에 저렴하게 이용할 수 있고, 호스팅 업체의 통합 관리를 받기 때문에 편리합니다. 인터넷에서 홈페이지를 윤영하려면 인터넷 공간에 자신의 홈페이지를 올려두어야만 합니다. 자신의 컴퓨터에 있으면 클라이언트가 접근할 수 없습니다. 클라이언트의 접속을 허용하기 위해서는 홈페이지와 연결된 주소가 있어야 합니다. 이 주소가 도메인 주소입니다.
트래픽은 전송량이라고 하며 어떤 통신장치나 시스템에 걸리는 부하를 말합니다. 트래픽 양이 지나치게 많으면 서버에 과부하가 걸려서 전체적인 시스템 기능에 장애를 일으킵니다. 트레픽 용량 계싼 방법은 텍스트와 이미지로 이루어진 1MB 용량의 웹페이지를 하루에 1000명이 접속하면 1000MB의 트래픽이 계산됩니다.
서버 호스팅은 고객이 단독 서버를 사용하는 형태입니다. 넓은 하드웨어 공간을 사용할 수 있고, 서버 운영/관리에 대한 직접적인 권한을 가질 수 있습니다. 또한, 빠른 데이터 전송 속도도 누릴 수 있습니다. 하지만 단독으로 서버를 사용하기 때문에 서버 비용이 많이 듭니다.
클라우드 서버는 서버 호스팅을 가상화한 것으로, 가상 서버를 단독으로 사용할 수 있는 형태입니다. 고객이 필요할 때마다 서버 자원을 늘리거나 축소하여 유연하게 서버를 이용할 수 있습니다. 하지만 하나의 가상 서버에 문제가 생기면 연결된 다른 가상 서버에도 문제가 생길 수 있는 단점이 있습니다.